

╔╠£½┐Ų╝╝š²╩Į░l(f©Ī)▓╝▓óķ_į┤┴╦┼c─Žč¾└Ē╣ż┤¾īW(xu©”) S-Lab║Žū„čą░l(f©Ī)Ą─╚½ą┬ČÓ─ŻæB(t©żi)─Żą═╝▄śŗ(g©░u) —— NEOŻ¼×ķ╚š╚šą┬ SenseNova ČÓ─ŻæB(t©żi)─Żą═ĄņČ©┴╦ą┬ę╗┤·╝▄śŗ(g©░u)Ą─╗∙╩»ĪŻ
ū„×ķąąśI(y©©)╩ūéĆ┐╔ė├Ą─ĪóīŹ(sh©¬)¼F(xi©żn)╔Ņīė┤╬╚┌║ŽĄ─įŁ╔·ČÓ─ŻæB(t©żi)╝▄śŗ(g©░u)Ż©Native VLMŻ®Ż¼NEO Å─ĄūīėįŁ└Ē│÷░l(f©Ī)Ż¼┤“ŲŲ┴╦é„Įy(t©»ng)“─ŻēK╗»”ĘČ╩ĮĄ─ĶõĶ¶Ż¼ęį“īŻ×ķČÓ─ŻæB(t©żi)Č°╔·”Ą─äō(chu©żng)ą┬įO(sh©©)ėŗ(j©¼)Ż¼═©▀^║╦ą─╝▄śŗ(g©░u)īė├µĄ─ČÓ─ŻæB(t©żi)╔Ņīė╚┌║ŽŻ¼īŹ(sh©¬)¼F(xi©żn)┴╦ąį─▄Īóą¦┬╩║══©ė├ąįĄ─š¹¾w═╗ŲŲŻ¼ųžą┬Č©┴x┴╦ČÓ─ŻæB(t©żi)─Żą═Ą─ą¦─▄▀ģĮńŻ¼ś╦(bi©Īo)ųŠų°╚╦╣żųŪ─▄ČÓ─ŻæB(t©żi)╝╝ąg(sh©┤)š²╩Į▀~╚ļ“įŁ╔·╝▄śŗ(g©░u)”Ą─ą┬Ģr┤·ĪŻ

šō╬─ŠW(w©Żng)ųĘŻ║https://arxiv.org/abs/2510.14979
┤“ŲŲŲ┐ŅiŻ║Ėµäe“Ų┤£É”Ż¼ōĒ▒¦“įŁ╔·”
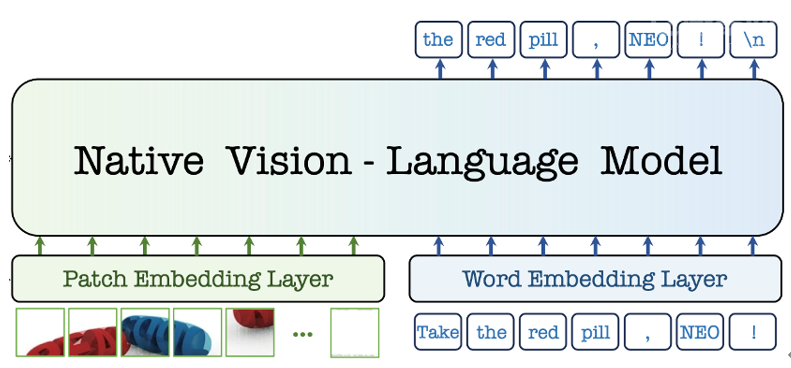
«ö(d©Īng)Ū░Ż¼śI(y©©)ā╚(n©©i)ų„┴„Ą─ČÓ─ŻæB(t©żi)─Żą═┤¾ČÓū±čŁ“ęĢėXŠÄ┤aŲ„+═Čė░Ų„+šZčį─Żą═”Ą──ŻēK╗»ĘČ╩ĮĪŻ▀@ĘN╗∙ė┌┤¾šZčį─Żą═Ż©LLMŻ®Ą─öU(ku©░)š╣ĘĮ╩ĮŻ¼ļm╚╗īŹ(sh©¬)¼F(xi©żn)┴╦łDŽ±▌ö╚ļĄ─╝µ╚▌Ż¼Ą½▒Š┘|(zh©¼)╔Ž╚įęįšZčį×ķųąą─Ż¼łDŽ±┼cšZčįĄ─╚┌║ŽāH═Ż┴¶į┌öĄ(sh©┤)ō■(j©┤)īė├µĪŻ▀@ĘN“Ų┤£É”╩ĮĄ─įO(sh©©)ėŗ(j©¼)▓╗āHīW(xu©”)┴Ģ(x©¬)ą¦┬╩Ą═Ž┬Ż¼Ė³Ž▐ųŲ┴╦─Żą═į┌Å═(f©┤)ļsČÓ─ŻæB(t©żi)ł÷Š░Ž┬Ż©▒╚╚ń╔µ╝░łDŽ±╝Ü(x©¼)╣Ø(ji©”)▓ČūĮ╗“Å═(f©┤)ļs┐šķgĮY(ji©”)śŗ(g©░u)└ĒĮŌŻ®Ą─╠Ä└Ē─▄┴”ĪŻ
╔╠£½ NEO ╝▄śŗ(g©░u)š²╩Ū×ķ┴╦ĮŌøQ▀@ę╗═┤³c(di©Żn)Č°╔·ĪŻįńį┌2024 ─ĻŽ┬░ļ─ĻŻ¼╔╠£½▒Ńį┌ć°ā╚(n©©i)┬╩Ž╚═╗ŲŲČÓ─ŻæB(t©żi)įŁ╔·╚┌║Žė¢(x©┤n)ŠÜ╝╝ąg(sh©┤)Ż¼ęįå╬ę╗─Żą═į┌ SuperCLUE šZčįįu£y ║═ OpenCompass ČÓ─ŻæB(t©żi)įu£yųąŖZ╣┌Ż¼▓ó╗∙ė┌▀@ę╗║╦ą─╝╝ąg(sh©┤)┤“įņ┴╦╚š╚šą┬ SenseNova 6.0Ż¼īŹ(sh©¬)¼F(xi©żn)ČÓ─ŻæB(t©żi)═Ų└Ē─▄┴”ŅI(l©½ng)Ž╚ĪŻų«║¾Ż¼į┌2025 ─Ļ 7 į┬░l(f©Ī)▓╝╚š╚šą┬ SenseNova 6.5 ═©▀^īŹ(sh©¬)¼F(xi©żn)ŠÄ┤aŲ„īė├µĄ─įńŲ┌╚┌║ŽŻ¼░čČÓ─ŻæB(t©żi)─Żą═ąįār▒╚╠ß╔² 3 ▒ČŻ¼▓óį┌ć°ā╚(n©©i)┬╩Ž╚═Ų│÷╔╠ė├╝ēäeĄ─łD╬─Į╗Õe═Ų└ĒĪŻ╔╠£½┤╦┤╬Ė³▀M(j©¼n)ę╗▓ĮŻ¼ÅžĄū▐Śē┴╦é„Įy(t©»ng)Ą──ŻēK╗»ĮY(ji©”)śŗ(g©░u)Ż¼Å─ĄūīėįŁ└Ē│÷░l(f©Ī)Ż¼═Ų│÷┴╦Å─┴ŃįO(sh©©)ėŗ(j©¼)Ą─ NEO įŁ╔·╝▄śŗ(g©░u)ĪŻ
╚²┤¾ā╚(n©©i)║╦äō(chu©żng)ą┬Ż║īŹ(sh©¬)¼F(xi©żn)ęĢėX║═šZčįĄ─╔ŅīėĮy(t©»ng)ę╗

NEO ╝▄śŗ(g©░u)ęįśOų┬ą¦┬╩║═╔ŅČ╚╚┌║Ž×ķ║╦ą─└Ē─ŅŻ¼═©▀^į┌ūóęŌ┴”ÖC(j©®)ųŲĪó╬╗ų├ŠÄ┤a║═šZ┴xė│╔õ╚²éĆĻP(gu©Īn)µIŠSČ╚Ą─Ąūīėäō(chu©żng)ą┬Ż¼ūī─Żą═╠ņ╔·Š▀éõ┴╦Įy(t©»ng)ę╗╠Ä└ĒęĢėX┼cšZčįĄ──▄┴”Ż║
įŁ╔·łDēKŪČ╚ļ (Native Patch Embedding)Ż║ ▐Śē┴╦ļx╔óĄ─łDŽ± tokenizerŻ¼═©▀^¬Ü(d©▓)äō(chu©żng)Ą─ Patch Embedding Layer (PEL) ūįĄūŽ“╔Žśŗ(g©░u)Į©Å─Ž±╦žĄĮį~į¬Ą─▀B└m(x©┤)ė│╔õĪŻ▀@ĘNįO(sh©©)ėŗ(j©¼)─▄Ė³Š½╝Ü(x©¼)Ąž▓ČūĮłDŽ±╝Ü(x©¼)╣Ø(ji©”)Ż¼Å─Ė∙▒Š╔Ž═╗ŲŲ┴╦ų„┴„─Żą═Ą─łDŽ±Į©─ŻŲ┐ŅiĪŻ
įŁ╔·╚²ŠSą²▐D(zhu©Żn)╬╗ų├ŠÄ┤a (Native-RoPE)Ż║ äō(chu©żng)ą┬ąįĄžĮŌ±Ņ┴╦╚²ŠSĢr┐šŅl┬╩Ęų┼õŻ¼ęĢėXŠSČ╚▓╔ė├Ė▀ŅlĪó╬─▒ŠŠSČ╚▓╔ė├Ą═ŅlŻ¼═Ļ├└▀m┼õā╔ĘN─ŻæB(t©żi)Ą─ūį╚╗ĮY(ji©”)śŗ(g©░u)ĪŻ▀@╩╣Ą├ NEO ▓╗āH─▄Š½£╩(zh©│n)▓Č½@łDŽ±Ą─┐šķgĮY(ji©”)śŗ(g©░u)Ż¼Ė³Š▀éõŽ“ęĢŅl╠Ä└ĒĪó┐ńļĮ©─ŻĄ╚Å═(f©┤)ļsł÷Š░¤o┐pöU(ku©░)š╣Ą─Øō┴”ĪŻ
įŁ╔·ČÓŅ^ūóęŌ┴” (Native Multi-Head Attention)Ż║ ßśī”▓╗═¼─ŻæB(t©żi)╠ž³c(di©Żn)Ż¼NEO į┌Įy(t©»ng)ę╗┐“╝▄Ž┬īŹ(sh©¬)¼F(xi©żn)┴╦╬─▒Š token Ą─ūį╗žÜwūóęŌ┴”║═ęĢėX token Ą─ļpŽ“ūóęŌ┴”▓ó┤µĪŻ▀@ĘNįO(sh©©)ėŗ(j©¼)śO┤¾Ąž╠ß╔²┴╦─Żą═ī”┐šķgĮY(ji©”)śŗ(g©░u)ĻP(gu©Īn)┬ō(li©ón)Ą─└¹ė├┬╩Ż¼Å─Č°Ė³║├Ąžų¦ō╬Å═(f©┤)ļsĄ─łD╬─╗ņ║Ž└ĒĮŌ┼c═Ų└ĒĪŻ
┤╦═ŌŻ¼┼õ║Žäō(chu©żng)ą┬Ą─ Pre-Buffer & Post-LLM ļpļAČ╬╚┌║Žė¢(x©┤n)ŠÜ▓▀┬įŻ¼NEO ─▄ē“į┌╬³╩šįŁ╩╝ LLM ═Ļš¹šZčį═Ų└Ē─▄┴”Ą─═¼ĢrŻ¼Å─┴Ńśŗ(g©░u)Į©ÅŖ(qi©óng)┤¾Ą─ęĢėXĖąų¬─▄┴”Ż¼ÅžĄūĮŌøQ┴╦é„Įy(t©»ng)┐ń─ŻæB(t©żi)ė¢(x©┤n)ŠÜųąšZčį─▄┴”╩▄ōpĄ─ļyŅ}ĪŻ
īŹ(sh©¬)£y▒Ē¼F(xi©żn)Ż║╩«Ęųų«ę╗Ą─öĄ(sh©┤)ō■(j©┤)Ż¼ūĘŲĮŲņ┼×╝ēąį─▄

į┌╝▄śŗ(g©░u)äō(chu©żng)ą┬Ą─“ī(q©▒)äėŽ┬Ż¼NEO š╣¼F(xi©żn)│÷┴╦¾@╚╦Ą─öĄ(sh©┤)ō■(j©┤)ą¦┬╩┼cąį─▄ā×(y©Łu)ä▌Ż║
śOĖ▀öĄ(sh©┤)ō■(j©┤)ą¦┬╩Ż║ āHąĶśI(y©©)Įń═¼Ą╚ąį─▄─Żą═ 1/10 Ą─öĄ(sh©┤)ō■(j©┤)┴┐Ż©3.9ā|łDŽ±╬─▒Š╩Š└²Ż®Ż¼NEO ▒Ń─▄ķ_░l(f©Ī)│÷Ēö╝ŌĄ─ęĢėXĖąų¬─▄┴”ĪŻ¤oąĶę└┘ć║Ż┴┐öĄ(sh©┤)ō■(j©┤)╝░Ņ~═ŌęĢėXŠÄ┤aŲ„Ż¼Ųõ║åØŹĄ─╝▄śŗ(g©░u)▒Ń─▄į┌ČÓĒŚ(xi©żng)ęĢėX└ĒĮŌ╚╬äš(w©┤)ųąūĘŲĮ Qwen2-VLĪóInternVL3 Ą╚Ēö╝ē─ŻēK╗»Ųņ┼×?z©Īi)Żą═Ī?br />
ąį─▄ū┐įĮŪęŠ∙║ŌŻ║ į┌ MMMUĪóMMBĪóMMStarĪóSEED-IĪóPOPE Ą╚ČÓĒŚ(xi©żng)╣½ķ_ÖÓ(qu©ón)═■įu£yųąŻ¼NEO ╝▄śŗ(g©░u)Š∙öž½@Ė▀ĘųŻ¼š╣¼F(xi©żn)│÷ā×(y©Łu)ė┌Ųõ╦¹įŁ╔· VLM Ą─ŠC║Žąį─▄Ż¼šµš²īŹ(sh©¬)¼F(xi©żn)┴╦įŁ╔·╝▄śŗ(g©░u)Ą─“Š½Č╚¤oōp”ĪŻ
śOų┬═Ų└Ēąįār▒╚Ż║ ╠žäe╩Ūį┌ 0.6B-8B Ą─ģóöĄ(sh©┤)ģ^(q©▒)ķgā╚(n©©i)Ż¼NEO į┌▀ģŠē▓┐╩ĘĮ├µā×(y©Łu)ä▌’@ų°ĪŻ╦³▓╗āHīŹ(sh©¬)¼F(xi©żn)┴╦Š½Č╚┼cą¦┬╩Ą─ļpųž▄S▀wŻ¼Ė³┤¾Ę∙ĮĄĄ═┴╦═Ų└Ē│╔▒ŠŻ¼īóČÓ─ŻæB(t©żi)ęĢėXĖąų¬Ą─“ąįār▒╚”═ŲŽ“┴╦śOų┬ĪŻ
ķ_į┤╣▓Į©Ż║śŗ(g©░u)Į©Ž┬ę╗┤· AI ╗∙ĄA(ch©│)įO(sh©©)╩®
╝▄śŗ(g©░u)╩Ū─Żą═Ą─“╣Ū╝▄”Ż¼ų╗ėą╣Ū╝▄į·īŹ(sh©¬)Ż¼▓┼─▄ų¦ō╬ŲČÓ─ŻæB(t©żi)╝╝ąg(sh©┤)Ą─╬┤üĒĪŻNEO ╝▄śŗ(g©░u)Ą─įńŲ┌╚┌║ŽįO(sh©©)ėŗ(j©¼)ų¦│ų╚╬ęŌĘų▒µ┬╩┼cķLłDŽ±▌ö╚ļŻ¼─▄ē“¤o┐pöU(ku©░)š╣ų┴ęĢŅlĪóŠ▀╔ĒųŪ─▄Ą╚Ū░čžŅI(l©½ng)ė“Ż¼īŹ(sh©¬)¼F(xi©żn)┴╦Å─ĄūīėĄĮĒöīėĪóČ╦ĄĮČ╦Ą─šµš²╚┌║ŽĪŻÅ─æ¬(y©®ng)ė├ĮŪČ╚Ż¼Č╦ĄĮČ╦Ą─“įŁ╔·ę╗¾w╗»”įO(sh©©)ėŗ(j©¼)Ż¼×ķÖC(j©®)Ų„╚╦Š▀╔ĒĮ╗╗źĪóųŪ─▄ĮKČ╦ČÓ─ŻæB(t©żi)Ēææ¬(y©®ng)ĪóęĢŅl└ĒĮŌĪó3DĮ╗╗ź╝░Š▀╔ĒųŪ─▄Ą╚ČÓį¬╗»ł÷Š░Ą─æ¬(y©®ng)ė├Ż¼╠ß╣®┴╦łį(ji©Īn)īŹ(sh©¬)Ą─╝╝ąg(sh©┤)ų¦ō╬ĪŻ
─┐Ū░Ż¼╔╠£½ęčš²╩Įķ_į┤╗∙ė┌ NEO ╝▄śŗ(g©░u)Ą─ 2B ┼c 9B ā╔ĘNęÄ(gu©®)Ė±─Żą═Ż¼ęį═Ųäėķ_į┤╔ńģ^(q©▒)į┌įŁ╔·ČÓ─ŻæB(t©żi)╝▄śŗ(g©░u)╔ŽĄ─äō(chu©żng)ą┬┼cæ¬(y©®ng)ė├ĪŻ╔╠£½┐Ų╝╝▒Ē╩ŠŻ¼ų┬┴”ė┌═©▀^ķ_į┤ģf(xi©”)ū„┼cł÷Š░┬õĄžļp▌å“ī(q©▒)äėŻ¼īó NEO ┤“įņ×ķ┐╔öU(ku©░)š╣Īó┐╔Å═(f©┤)ė├Ą─Ž┬ę╗┤· AI ╗∙ĄA(ch©│)įO(sh©©)╩®Ż¼═ŲäėįŁ╔·ČÓ─ŻæB(t©żi)╝╝ąg(sh©┤)Å─īŹ(sh©¬)“×(y©żn)╩ęū▀Ž“ÅVĘ║Ą─«a(ch©Żn)śI(y©©)╗»æ¬(y©®ng)ė├Ż¼╝ė╦┘śŗ(g©░u)Į©Ž┬ę╗┤·«a(ch©Żn)śI(y©©)╝ēįŁ╔·ČÓ─ŻæB(t©żi)╝╝ąg(sh©┤)ś╦(bi©Īo)£╩(zh©│n)ĪŻ
Github ķ_į┤ŠW(w©Żng)ųĘŻ║https://github.com/EvolvingLMMs-Lab/NEO