

FineReader Engine12╩ŪABBYY╚½├µ└¹ė├╚╦╣żųŪ─▄┼cÖCŲ„īW┴ĢĄ─ę╗┤¾┴”ū„ĪŻėą┘ćė┌╚╦╣żųŪ─▄┼cÖCŲ„īW┴Ģ╦ŃĘ©Ż¼ą┬░µ▒Šī”ūRäe▀^│╠▀Mąą┴╦ā×╗»║═š{š¹Ż¼╠ß╣®╬─ÖnĘųŅÉĪó╬─Önųąī”Ž¾┼cłD▒ĒūRäeĪóČÓĘNšZčįūRäeęį╝░▓╝ŠųųžĮ©Ą╚ÅŖ┤¾╣”─▄Ż¼┐╔Ä═ų·▄ø╝■╣½╦ŠĪóŽĄĮy╝»│╔╔╠║═Ųõ╦³Ų¾śI┐═æ¶ķ_░lĖ³Ė▀┘|┴┐Ą─╬─Ön╠Ä└ĒĮŌøQĘĮ░ĖĪŻ
“ABBYY FineReader Engine 12ØMūŃ┴╦į┌╠ōöMÖC╗“įŲČ╦╩╣ė├OCR║═öĄō■▓Č½@Ą─æ¬ė├│╠ą“▓╗öÓį÷ķLĄ─ąĶŪ¾ĪŻįōSDK╩╣Ų¾śI║═ĮM┐Ś─▄ē“ūįė╔Ąžķ_░lūŅ▀m║ŽŲõśIäš─┐ś╦Ą─▄ø╝■Ż¼ŲõŽ╚▀MĄ─╣”─▄║═┐╔ūRäe200ėÓĘNšZčįĄ─ÅŖ┤¾─▄┴”Ż¼īóėą┴”ĄžÄ═ų·Ė„ŅÉ┐═æ¶▀M▄Ŗą┬╩ął÷Ż¼”ABBYYžōž¤SDKĄ─╚½Ū“«aŲĘĀIõNĖ▀╝ē┐é▒O└ū╝{·▒Ż║š(Rainer Pausch)▓®╩┐įušōšfĪŻ
OCRūRäe─▄┴”į┘╔²╝ē ā╔┤¾┴┴³cśõ┴óąąśIą┬ś╦ŚU
ę╗ų▒ęįüĒŻ¼ABBYYęįŲõ╩└ĮńŅIŽ╚Ą─OCR╝╝ągę²ŅIąąśIĄ─┘|┴┐║═┐╔┐┐ąįś╦£╩ĪŻ═©▀^FineReader Engine 12 ķ_░lĄ─æ¬ė├│╠ą“┐╔Š▀éõ╬─▒ŠūRäeĪóPDF▐DōQ║═öĄō■▓Č½@╣”─▄Ż¼┐╔īóÆ▀├Ķ╬─Ön▐DōQ×ķ┐╔╦č╦„Ą─PDFĪóPDF/AĪóWord╗“Excel╬─ÖnŻ¼▓ó┐╔įL墚šŲ¼ĪóŲ┴─╗ĮžłDĪó╣żśI’@╩ŠŲ„╗“Ų¹▄ćāx▒Ē░Õ║═ą┼ŽóŖ╩śĘŽĄĮy╔ŽĄ─öĄō■ĪŻ╩╣ė├įō╣żŠ▀░³Ż¼æ¬ė├│╠ą“─▄ē“īóTIFFÄņ▐DōQ×ķPDFĪóPDF/AĪóWord╗“Ųõ╦¹Ė±╩ĮŻ¼▓ó£╩┤_╠ß╚ĪūųČ╬ųĄĪŻ
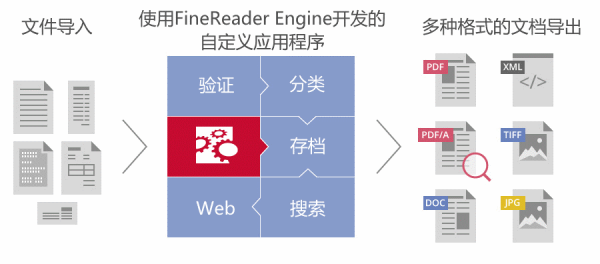
═¼ĢrŻ¼ą┬░µ▒ŠĄ─SDKĖ³ōĒėą▓╝ŠųųžĮ©╣”─▄║═ČÓšZčį╬─▒Š╠Ä└Ē─▄┴”ā╔┤¾┴┴³cĪŻ
FineReader Engine 12Ą─ÅŖ╗»▓╝ŠųųžĮ©ę└┘ćė┌ABBYYūį▀mæ¬╬─ÖnūRäe╝╝ąg┼cÖCŲ„īW┴Ģ╦ŃĘ©Ż¼į÷╝ė┴╦ūRäe║═▀ĆįŁ╬─▒ŠŲĮ║ŌÖ┌Ą─╣”─▄Ż¼▀Ćī”ūRäe▒ĒĖ±╝░Ųõ▓╝ŠųųžĮ©╣”─▄▀Mąą╔²╝ēĪŻŲ¾śI▓╗āH┐╔ęįäōĮ©┐╔╦č╦„┼c┐╔ŠÄ▌ŗĄ─╬─ÖnŻ¼Č°Ūę▀@ą®╬─Ön┼cÆ▀├Ķ╗“┼─özĄ─įŁ╝■═Ļ╚½Ųź┼õĪŻ▀@ę╗╣”─▄ī”ė┌Ų¾śIėąą¦╠Ä└Ē┤¾┴┐žöäš╬─ÖnśOŲõųžę¬ĪŻ
ę└═ąÅŖ┤¾Ą─╚╦╣żųŪ─▄╝╝ągŻ¼FineReader Engine 12┐╔ų¦│ų208ĘNšZčįĪŻįōą┬░µ▒ŠSDKī”╚ššZĄ─╣ŌīWūųĘ¹ūRäe(OCR)╝╝ąg▀Mąą┴╦Ė─▀MŻ¼▓ó╝ė╚ļ▓©╦╣šZū„×ķę╗ĘNą┬Ą─ūRäešZčį, ╩╣ABBYY└^└m▒Ż│ųį┌┐╔ūRäešZčį┐éöĄ╔ŽĄ─ŅIŽ╚ĪŻĖ³╝ėųĄĄ├ūóęŌĄ─╩ŪŻ¼┤╦┤╬╔²╝ēÅŖ╗»┴╦ī”═¼ę╗╬─Önųą│÷¼FĄ─ČÓĘNšZčį▀Mąą╠Ä└ĒĄ──▄┴”Ż¼┤¾┤¾╝ėÅŖ┴╦ČÓšZčį╬─ÖnĄ─ūRäe£╩┤_Č╚Ż¼▓ó┐╔╔·│╔▒Ż┴¶įŁ╩╝▓╝ŠųĄ─┐╔╦č╦„║═┐╔ŠÄ▌ŗĄ─öĄūųĖ▒▒ŠĪŻ
Ė▀┐╔ė├ąį║═ČÓ┼õ╠ūŲĮ┼_ ų·┴”Ų¾śIōīš╝╩ął÷
─┐Ū░Ż¼▀mė├ė┌WindowsĪóLinuxĪóMacŽĄĮyęį╝░ŪČ╚ļ╩ĮŽĄĮyĄ─FineReader Engine 12 ░µ▒ŠęčĮøį┌╚½Ū“╔Ž╩ąĪŻ įōSDK═¼Ģr┐╔ęį╝»│╔ĄĮį┌“░ó└’įŲ”║═╬ó▄øįŲ(Microsoft Azure)Ą╚įŲŲĮ┼_╔Ž▀\ąąĄ─æ¬ė├│╠ą“ųąŻ¼▓óų¦│ų╠ōöMŁhŠ│Ż¼═žīÆ┴╦╠ß╣®▄ø╝■æ¬ė├║═Ę■䚥─ĘČć·ĪŻ
═¼ĢrŻ¼FineReader Engine 12▀Ć╠ß╣®┴╦▌p╦╔╝»│╔ĪóŅA┼õų├╣żŠ▀Īó┤·┤a╩Š└²Ą╚Ųõ╦¹ĮM╝■Ż¼┐╔┤¾┤¾┐sČ╠OCRæ¬ė├«aŲĘĄ─ķ_░lĢrķgŻ¼ėąų·ė┌▄ø╝■╣½╦ŠĪóŽĄĮy╝»│╔╔╠║═Ų¾śIį┌«öĮ±┐ņ╦┘░lš╣Ą─╔╠śIŁhŠ│ųą│¼įĮĖéĀÄī”╩ųŻ¼š╝Ą├╩ął÷Ž╚ÖCĪŻ