
▀@Äū╠ņ░┘Č╚▓╗öÓ│÷ą┬Ż¼ūī╚╦─┐▓╗ŽŠĮėĪŻį┌śO║å╩ūĒōų«║¾Ż¼ĪČąĪĢr┤·3ĪĘĄ─░┘Č╚ų¬ūRłDūVę▓Ū─╚╗į┌╦č╦„Ēō╔ŽŠĆĪŻĪČąĪĢr┤·3ĪĘ┤¾¤ßų«ļHŻ¼ŲõÕeŠCÅ═ļsĄ─╚╦╬’ĻPŽĄ▓ó▓╗╩Ū├┐éĆė^▒ŖČ╝─▄└ĒŪÕŻ¼░┘Č╚═©▀^šŲ╬šĄ─ų¬ūRłDūVöĄō■ų▒ĮėĮo│÷┴╦ŪÕ╬·Ą─ŠWĀŅĻPŽĄŻ¼┐╔ęĢ╗»Īóų¦│ų╗źäėĪŻ╣Pš▀ūóęŌĄĮ▀@éĆ«aŲĘĄ─ŠWųĘŪ░ŠY╩Ūtupu.baidu.comŻ¼┐┤üĒĮėŽ┬üĒ░┘Č╚▒ž╚╗Ģ■═Ų│÷Ė„ĘN¬Ü┴óĄ─“łDūV”Ēō├µŻ¼ų¬ūRłDūV«aŲĘ┐±ŽļŪ·ęč╚╗ūÓĒæĪŻ

╬ęéāęčÅ─ą┼ŽóĢr┤·▀M╚ļų¬ūRĢr┤·
╚ń╣¹ę¬ī”╗ź┬ōŠW▀MąąĘųīėŻ¼╦³┤¾Ė┼┐╔ęįĘų×ķ╦─īėĪŻ
ūŅĄūīė╩ŪīóīŹ¾w╩└Įń▒╚╠ž╗»Ą─“öĄō■”ĪŻČ■▀MųŲ┤µā”╝╝ągĪó╬─╝■ĮYśŗęį╝░öĄō■ÄņĮŌøQĄ─▒Ń╩Ū“öĄō■”Ą─å¢Ņ}Ż¼Į±╠ņätęč▀M╚ļ“┤¾öĄō■”Ģr┤·ĪŻ╦č╦„ę²Ūµ┤╦Ģr▒╚Ų┤Ą─╩ŪöĄō■╦„ę²┴┐║═╦č╦„ĮY╣¹╝»Ą─┤¾ąĪĪŻ
öĄō■╔Žę╗īėät╩Ūą┼ŽóŻ¼öĄō■╩ŪĖ³Ąūīė╩ŪĮoÖCŲ„Ą─Ż¼ą┼Žóät╩ŪĮo╚╦ūxĄ─Ż¼ėą▀ē▌ŗėąøQ▓▀ģó┐╝ārųĄŻ¼öĄō■╠Ä└Ēų«║¾▒Ń│╔×ķą┼ŽóŻ¼ą┼ŽóĖ’├³Ą─šfĘ©š²╩ŪėĪūC┴╦╗ź┬ōŠWĄ─║╦ą─╩Ūą┼ŽóĪŻ▀@Ģr║“╦č╦„ę²Ūµ║╦ą─╩ŪŠ½£╩Ąž▀BĮė╚╦┼cą┼ŽóĪŻ
ą┼Žó╔Žę╗īėŠ═╩Ūų¬ūRŻ¼ą┼ŽóųąėąārųĄĄ─▓┐Ęų│┴ĄĒŽ┬üĒ┼c╚╦ŅÉĘe└█Ą─ų¬ūR¾wŽĄ╚┌║Žį┌ę╗ŲŻ¼Š═│╔×ķ╗ź┬ōŠWĄ─ų¬ūRĪŻWIKI░┘┐ŲĪó░┘Č╚ų¬Ą└║═ų¬║§▀@ą®«aŲĘ▒Š┘|╔ŽČ╝╩Ūć·└@ų¬ūRį┌▐DĪŻą┼Žó▀^▌d│╔×ķ╚╦ŅÉžōō·Ż¼ų¬ūR│┴ĄĒät│╔×ķ╚╦ŅÉĄ─žöĖ╗ĪŻ╗ź┬ōŠWų¬ūRłDūV▀h│¼łDĢ°^Ą╚é„ĮyĄ─ų¬ūR│┴ĄĒĘĮ╩ĮŻ¼ārųĄ╩«Ęų┐╔ė^ĪŻ╦č╦„ę²Ūµį┌ų¬ūRĢr┤·Ą─ārųĄät╩ŪÄ═ų·╚╦éāšęĄĮ£╩┤_Ą─┤░ĖĪŻ
ų¬ūRį┘═∙╔Ž╩ŪųŪ╗█ĪŻ╚╦ŅÉ╗∙ė┌ų¬ūRŻ¼Ė∙ō■╬’└Ē╩└ĮńęÄ┬╔šęĄĮĄ─ĮŌøQīŹļHå¢Ņ}Ą──▄┴”▒╗Üw╝{×ķųŪ╗█ĪŻų¬ūR╩Ū“╬ęų¬Ą└╩▓├┤”▀Ć▓╗ūŃęįĮŌøQ“ū÷╩▓├┤Īó╚ń║╬ū÷”▀@śėĄ─å¢Ņ}Ż¼▓╗Ę”ėą╚╦ØMĖ╣ĮøŠ]Ą½į┌╔·╗Ņ║═ØL╣żū„ųą╚▒Ę”ųŪ╗█ĪŻĄ½ųŪ╗█┼cų¬ūRŽÓ▌oŽÓ│╔Ż¼ųŪ╗█ūīų¬ūRĖ³╝ėžSØMŻ¼ų¬ūRät╩ŪųŪ╗█Ą─Ū░╠ßĪŻ
╬ęéāęčĮøÅ─ą┼ŽóĢr┤·▀M╚ļĄĮų¬ūRĢr┤·ĪŻį┌ą┼Žó▀^▌dĄ─┤¾▒│Š░ų«Ž┬Ż¼į┌╗ź┬ōŠWŪų╬gīŹ¾w╩└ĮńĄ─┌ģä▌Ž┬Ż¼ĮŌøQ¼FīŹ╩└ĮńĄ─īŹļHå¢Ņ}Ė³╝ėųžę¬ĪŻ╦č╦„ę²ŪµĄ─╩╣├³▐Dūā×ķ▀BĮė╚╦┼cĘ■䚯¼Č°▓╗į┘ų╗╩Ū▀BĮėą┼ŽóŻ¼╦³ąĶę¬£╩┤_Ąž╗ž┤╚╦éāĄ─īŹļHå¢Ņ}Ż¼Įo╚╦éā╠ß╣®═ĻéõĄ─Ę■äšĪŻų¬ūRłDūV│╔×ķųŪ╗█╦č╦„Ą─╗∙╩»ĪŻ
░┘Č╚ų¬ūRłDūV▀M╚ļŲš╝░Ū░ę╣
ų¬ūRłDūV(Knowledge Graph)▒╗ĘQ×ķ┐ŲīWų¬ūRłDūVŻ¼“╦³’@╩Šų¬ūR░lš╣▀M│╠┼cĮYśŗĻPŽĄĄ─ę╗ŽĄ┴ą▓╗═¼łDą╬Ż¼ė├┐╔ęĢ╗»╝╝ąg├Ķ╩÷ų¬ūR┘Yį┤╝░Ųõ▌d¾wŻ¼═┌Š“ĪóĘų╬÷ĪóśŗĮ©Īó└LųŲ║═’@╩Šų¬ūR╝░╦³éāų«ķgĄ─ŽÓ╗ź┬ōŽĄ”ĪŻ
║åå╬šfŻ¼ų¬ūRłDūV╩Ū╦č╦„ĮY╣¹¾wŽĄ╗»ĪóĻP┬ō╗»║═┐╔ęĢ╗»Ż¼╚╬║╬ę╗éĆ╦č╦„šłŪ¾Č╝─▄Ą├ĄĮę╗éĆų¬ūR¾wŽĄŻ¼▓╗į┘ų╗╩ŪŠĆąįĄ─ŠWųĘ┴ą▒ĒŻ¼Č°╩ŪŠWĀŅų¬ūRĮY³cŻ¼Ų®╚ń╦č╦„“ąĪĢr┤·”▒Ń┐╔┐┤ĄĮĮŪ╔½ĻPŽĄłDŻ¼╦č╦„Ąž├¹ät┐╔ęį┐┤ĄĮĄžłDĪó╠ņÜŌĪó┬├ė╬Š░³cĄ╚ĻP┬ōą┼ŽóĪŻ
ų¬ūRłDūVĦüĒÄūéĆĖ─ūāĪŻę╗╩ŪĮY╣¹Ė³╝ė£╩┤_ĪŻė├æ¶╦č╦„ĻPµIį~┐╔─▄ėąČÓųžęŌ╦╝Ż¼ų¬ūRłDūV┐╔ęįš╣╩ŠūŅ╚½├µĄ─ą┼ŽóŻ¼Ė³ėąÖCĢ■├³ųąė├æ¶ąĶŪ¾;Č■╩ŪĮY╣¹░³└©╚½├µĄ─š¬ę¬Ż¼ĪČąĪĢr┤·3ĪĘłDūV▒Ń┐╔┐┤ĄĮĻP┬ōĄ─č▌åTĪóū„š▀ĮķĮB╔§ų┴╬ó▓®ŽÓĻPįÆŅ};╚²╩Ū╦č╦„Ė³ÅVĖ³╔ŅŻ¼═©▀^ų¬ūRłDūVĮ©┴óĄ─ĻPŽĄūīė├æ¶┐╔ęį═©▀^╗źäėĪó³cō¶═žš╣╦č╦„Ą─╔ŅČ╚║═ÅVČ╚ĪŻ
Ė³£╩ĪóĖ³ÅVĪóĖ³╔ŅĄ─╦č╦„╩Ū░┘Č╚ę╗ų▒į┌ūĘŪ¾Ą──┐ś╦ĪŻė╚Ųõ╩Ūį┌┤¾┴”░lš╣ęŲäė╦č╦„Ą─«öŽ┬Ż¼Ė³╩ŪąĶę¬ūī╦č╦„ū÷ĄĮŠ½£╩¤o▒╚Ż¼ęįĮĄĄ═ė├æ¶▌ö╚ļ║═▀xō±│╔▒ŠĪŻ«ö░┘Č╚śO║å╩ūĒō╔ŽŠĆŻ¼¤oąĶė├æ¶▀xō±ŅlĄ└ĢrŻ¼╦³Ą─ĮY╣¹▒ž╚╗ę¬ūŃē“Š½£╩║═╚½├µŻ¼ō¶ųąė├æ¶ąĶŪ¾▓┼ąąŻ¼ų¬ūRłDūVĄ──▄┴”š²į┌ė┌┤╦ĪŻ
░┘Č╚ę╗ų▒Č╝╩«ĘųųžęĢų¬ūRłDūV▓óŪęėąŽ╚╠ņā×ä▌Ż¼╚ź─Ļ▒ŃĻæĻæ└m└m│÷¼F░┘Č╚ų¬ūRłDūVĄ─Ž¹ŽóŻ¼─▄╗ž┤“Ą┌╚²éĆūų╩Ū’LĄ─│╔šZ”Īó“ųx÷¬õhĄ─Ū░Ų▐Ą─ā║ūėĄ─░ų░ųĄ──Ļ²g”▀@śėĄ─═Ų└Ēå¢Ņ}Š═╩Ūų¬ūRłDūVĄ─æ¬ė├ĪŻĮY╣¹Ēōėęé╚Ą─ĻP┬ōĮY╣¹Ż¼ę▓╩Ūų¬ūRłDūVĄ─æ¬ė├ĪŻ▒Š┤╬ų¬ūRłDūVĄ─┐╔ęĢ╗»š╣¼FŻ¼╩Ū═©▀^░┘Č╚ā╚▓┐Ū░Č╦ķ_į┤«aŲĘEchartsīŹ¼FĄ─ĪŻ
ĪČąĪĢr┤·3ĪĘų¬ūRłDūV╔ŽŠĆĪótupu.baidu.comė“├¹│÷¼Fęį╝░░┘Č╚śO║å╩ūĒō╔ŽŠĆ▀@ÄūéĆ█EŽ¾ät▒Ē├„Ż¼░┘Č╚ų¬ūRłDūV«aŲĘ┐±ŽļŪ·ęč╚╗ūÓĒæĪŻ
┼cGoogleĪóBing║═Facebookų¬ūRłDūVĄ─▓╗═¼╦╝┬Ę
į┌╝╝ąg╔ŽGoogle║═Bingę╗ų▒┼c░┘Č╚Ęų═ź┐╣ČYŻ¼į┌ų¬ūRłDūV╔ŽŻ¼╚²╝ęČ╝ėąų°║▄ÅŖĄ─Ęe└█ĪŻ╚ź─Ļ╔ńĮ╗Š▐Ņ^Facebookę▓═Ų│÷Graph Search▀M╚ļ╔ńĮ╗łDūV╦č╦„ĪŻ
Googleį┌2012─Ļ═Ų│÷ų¬ūRłDūV«aŲĘŻ¼▓╗╣▄ė├æ¶╦č╦„Ą─ĻPµIį~╩Ū┤·▒Ē┴╦Ąžś╦Īó├¹╚╦Īó│Ū╩ąĪóŪ“ĻĀ├¹ĪóļŖė░ĪóīŻśIį~šZ▀Ć╩Ūę╗ĘN▓╦Ą─ū÷Ę©Ż¼Google Ą─“ų¬ūRłDūV”Č╝┐╔ęįīó╦č╦„ĮY╣¹Ą─ų¬ūR¾wŽĄ═Ļš¹Ą─│╩¼F│÷üĒĪŻ┤╦═ŌŻ¼GoogleėąSearch Plus Your World▀@ę╗ĮY║ŽGoogle+Ą─╔ńĮ╗╦č╦„«aŲĘĪŻ

Bingį┌ųąć°═Ų│÷┴╦╚╦┴óĘĮ╔ńĮ╗╚╦ļHĻPŽĄ╦č╦„ę²ŪµŻ¼─Ń┐╔ęį▓ķ┐┤ę╗éĆ╚╦├¹Ą─¤ßČ╚Ż¼TAĄ─ĻPŽĄŠWĮjłDŻ¼TAūŅėH├▄Ą─║├ėčŻ¼▀@┐Ņ«aŲĘ╗∙ė┌╚½ŠWWEBöĄō■ęį╝░ą┬└╦╬ó▓®Ą─ķ_Ę┼öĄō■ĪŻė╔ė┌ų╗─▄╦č╦„╚╦ļHĻPŽĄŻ¼┼cŲõ╦¹ų¬ūRĘųļx┴╦Ż¼ę“┤╦╚╦┴óĘĮ▓óø]ėą╩▓├┤Ų╔½ĪŻ
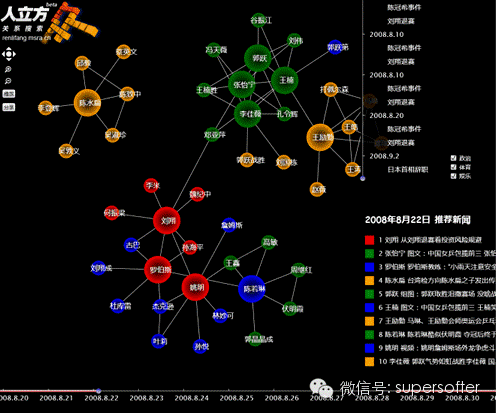
ļSų°Facebook GraphSearchĄ─═Ų│÷Ż¼Bingīóų¬ūRłDūV┼c╔ńĮ╗ŠWĮjĮY║ŽŲüĒĄ─Č©╬╗’@╚╗╩Ūī└▐╬Ą─ĪŻę“×ķBing▓óø]ėąūį╝║Ą─╔ńĮ╗öĄō■——į┌Space║═MSNŠ∙ą¹Ėµ╩¦öĪĄ─ŪķørŽ┬ĪŻ

Facebook Graph Search╩Ū╗∙ė┌╔ńĮ╗łDūVĄ─╦č╦„Ż¼┐╔ęį╦č╦„“┬Õ╔╝┤ēXXĮųĄ└ūŅĮ³ę╗─ĻĮė┤²╬ęĄ─┼¾ėčūŅČÓĄ─▓═Åd”▀@śėĄ─å¢Ņ}ĪŻGraphSearchø]ėą┤¾½@│╔╣”Ż¼ę“×ķFacebookų╗ėąĘŌķ]Ą─╔ńĮ╗öĄō■Ż¼╗∙ė┌▀@ą®öĄō■─▄ē“ĮM┐ŚĄ─ų¬ūRŻ¼─▄ē“Įo│÷Ą─ĮY╣¹Ż¼─▄ē“ØMūŃĄ─╦č╦„ł÷Š░Č╝╩«ĘųėąŽ▐Ż¼╦³ų╗╩Ūę╗┐Ņ▀^Ą├╚źĄ─šŠā╚╦č╦„ĪŻ
Bing║═FacebookĄ─į┌łDūV╦č╦„╔ŽĄ─╩¦└¹šf├„┴╦╔ńĮ╗╝╚ĘŪ▒žę¬Śl╝■ęÓĘŪ│õĘųŚl╝■ĪŻGoogle║═░┘Č╚═Ļ╚½Å─╦č╦„│÷░l╗∙ė┌╩«ČÓ─Ļ│┴ĄĒĄ─ų¬ūRłDūVĪóė├æ¶öĄō■Ż¼└¹ė├╔├ķLĄ─┤¾öĄō■║═╔ŅČ╚īW┴Ģ╦ŃĘ©Ż¼Ę┤Č°┐╔ęį░čų¬ūRłDūVū÷Ą├Ė³╝ė╚½├µĪ󊽣╩║══ĻéõĪŻ
Google║═░┘Č╚į┌ų¬ūRłDūV╠Į╦„╔Ž▀Ć╩ŪĢ■ėą╦∙▓╗═¼ĪŻGoogleų¬ūR║╦ą─üĒūįWIKIPEDIAĪóFreebaseĄ╚ŠWšŠŻ¼░┘Č╚05─Ļū¾ėęķ_╩╝Ą─UGCų¬ūR«aŲĘæ┬įŻ¼╩╣ų«ōĒėąÅŖ┤¾Ą─ūįėąų¬ūRłDūVŻ¼ĘųäeüĒūį░┘┐ŲĪóų¬Ą└║═┘N░╔▀@ą®«aŲĘĄ─öĄā|ŚlöĄō■║═ĻPŽĄĪŻ─┐Ū░░┘Č╚Ą─ų¬ūRłDūVęčĮø║Ł╔w╩«Äū┤¾ŅIė“Ż¼öĄ╩«éĆŅÉäeŻ¼ōĒėą╔Žā|īŹ¾w┴┐ĪŻ═©▀^śŗĮ©║Ļ┤¾Ą─ų¬ūRŠWĮjŻ¼š¹║Ž╦ķŲ¼╗»ą┼ŽóŻ¼į┘ęįłD╬─▓ó├»Ą─ĘĮ╩Įš╣¼F│÷üĒŻ¼╚╦éā▒Ń┐╔ęįį┌▌p³c╩¾ś╦Ą─Ų¼┐╠Ż¼čĖ╦┘½@╚Īų¬ūRĪóšęĄĮ╦∙Ū¾ĪŻ
ųĄĄ├ę╗╠ߥ─╩ŪŻ¼ūįĮ±─ĻęįüĒŻ¼░┘Č╚į┌╦č╦„ĮY╣¹Ēō╔ŽŅl│÷ą┬«aŲĘŻ¼│²┴╦╚╦╬’ĻPŽĄłDūV═ŌŻ¼į┌ėąĮ╣³c╩┬╝■╚ń£½╬©ėå╗ķĄ╚ą┬┬ä░l╔·ĢrŻ¼╦č╦„ĮY╣¹ėęé╚▒ŃĢ■│╩¼F│÷ŽÓĻP╚╦╬’ĻPŽĄĄ─ųŪ─▄═Ų╦]Ż╗├┐ĘĻ╩└Įń▒ŁĄ╚ųž┤¾┘É╩┬╗Ņäė┼e▐kĢrŻ¼╝┤ĢrĖ³ą┬Ą─Ģrķg├}ĮjłDūVę▓Ģ■ŪÕ╬·š╣¼Fį┌ėęé╚Ż╗Č°ė├æ¶╦č╦„“╣╩īm”Īó“ŅU║═ł@”Ą╚Š░ģ^Ż¼┐╔ų▒ĮėĄ├ĄĮŠ░³cĄžłDĪó╚╦╚║Ęų▓╝łDĪóų▄▀ģĮ╗═©ą┼ŽóĪóŠ░³c═Ų╦]Ą╚ą┼Žó……
▒Ŗ╦∙ų▄ų¬Ż¼ų¬ūRłDūVī”“šZ┴xūRäe”╝╝ągķTÖæśOĖ▀Ż¼ī”╔ńĢ■╗»ķ_į┤ā╚╚▌ėą║▄ÅŖĄ─ų¦ō╬ąĶŪ¾Ż¼Ūę╩Ūę└┘ć┤¾┴┐ė├æ¶Ą─ąą×ķöĄō■ÄņĄ─«aŲĘą╬æBĪŻ░┘Č╚╦č╦„▒Š╔ĒŠ═╩Ūę╗éĆ┤¾öĄō■üĒį┤Ż¼═¼Ģr░┘Č╚▀ĆōĒėąüĒūįŽ±░┘Č╚░┘┐ŲĪó░┘Č╚ų¬Ą└Īó░┘Č╚╬─ÄņĄ╚«aŲĘĄ─ČÓĘĮ├µöĄō■ų¦│ųŻ¼▀@ą®╣▓═¼īó░┘Č╚┤“įņ│╔ę╗éĆöĄō■║Į─ĖæČĘ╚║Ż¼┤┘╩╣░┘Č╚─▄ē“į┌ę╗─ĻĢrķg└’═Ļ│╔┴╦Į³░┘ā|īŹ¾wų¬ūRłDūVĄ─śŗĮ©▓óŪęīŹ¼F┴╦ŲĮ┼_╗»Ż¼▀@śė░┘Č╚ų¬ūRłDūVŠ═─▄ē“┐ņ╦┘ŪąōQų¦ō╬ČÓéĆ«aŲĘĄ─░lš╣ĪŻ
ų¬ūRłDūV┐╔ęįūīė├æ¶Ą├ĄĮ╚½ą┬Ą─╦č╦„¾w“ׯ¼ūīė├æ¶Ė³┐ņ╦┘ĮėĮ³┤░Ė║═Ę■äšĪŻ╣Pš▀╦╝┐╝Ą─ę╗éĆå¢Ņ}╩ŪŻ║└^░ó└ŁČĪų«║¾Ż¼ų¬ūRłDūV╩ŪĖ³ÅŖ┤¾Ą─ė├æ¶ąĶŪ¾ØMūŃĘĮ╩Įåß?