
2.2 Ųź┼õ
┐╔ęį▒╗├Ķ╩÷│╔╚ńŽ┬┴„│╠Ż║S1Ż║ė├æ¶═©▀^┴─╠ņĮń├µŽ“ŽĄĮy╠ß│÷ę╗éĆįÆŅ}Ż╗S2Ż║ŽĄĮyī”įōįÆŅ}▀MąąĘųį~╠Ä└ĒŻ╗S3Ż║į┌ŽĄĮyų¬ūRÄņųąīżšę┼cįōįÆŅ}Ųź┼õĄ─įÆšZ╗žÅ═ė├æ¶ĪŻ
╗∙ė┌į~ĄõĄ─Ęųį~╦ŃĘ©Ęų×ķį~Ąõ╝ė▌dĪóŅA╠Ä└ĒĪóūŅ┤¾Ųź┼õĪóŲń┴xŽ¹ĮŌÄūéĆļAČ╬ĪŻ
ŲõŠ▀¾w┴„│╠╚ńŽ┬Ż║
S1Ż║ŅA╠Ä└ĒļAČ╬Ż¼░┤šš╠ž╩ŌūųĘ¹(ėó╬─ūų─ĖĪóöĄūųĪóś╦³cĘ¹╠¢Ą╚)īó┤²Ęų╬÷╬─▒Š▀MąąöÓŠõŻ¼īó┤²ŪąĘųĄ─╬─▒ŠŪąĘų×ķų╗ėąųą╬─Ą─Č╠ŠõūėŻ¼▀@ą®Šõūė╩ŪŽ┬ę╗▓ĮĘųį~╠Ä└ĒĄ─╗∙▒Šå╬╬╗Ż╗
Ż©┼eéĆ└§ūėŻ║▌ö╚ļ“asdfadf¢|▒▒ĤĘČ┤¾īW╣■╣■╣■dfadflakfl(*^__^*) ╬¹╬¹……”Ż¼simių╗Ģ■ī”ŲõųąĄ─ųą╬─“¢|▒▒ĤĘČ┤¾īW╣■╣■╣■╬¹╬¹”ū÷│÷Ēææ¬Ż╗▌ö╚ļ“(*^__^*)”ĢrŻ¼▌ö│÷“I have no response.”Ż®
S2Ż║ī”öÓŠõ│÷üĒĄ─Šõūė▀MąąļpŽ“ūŅ┤¾Ųź┼õŻ©ļpŽ“Ųź┼õŻ¼ķLį~ā׎╚Ż®Ęųį~Ż¼Ęųį~║¾Ą─ĮY╣¹ū„×ķS3Ą─▌ö╚ļŻ╗
Ż©┼eéĆ└§ūėŻ║▌ö╚ļ“¢|Š®╣┼░═▒╚éÉ”Ż¼š²Ž“┼cĘ┤Ž“Ūąį~ĮY╣¹Š∙×ķĪČ¢|Š®Ż¼╣┼░═▒╚éÉĪĘŻ¼ķLį~ā׎╚Ż¼╦∙ęįsimių╗ī”“╣┼░═▒╚éÉ”ū÷│÷Ēææ¬Ż╗▌ö╚ļ“╣┼░═▒╚éÉ░ŻĘŲĀ¢ĶF╦■”Ż¼š²Ž“┼cĘ┤Ž“Ūąį~ĮY╣¹Š∙×ķĪČ╣┼░═▒╚éÉŻ¼░ŻĘŲĀ¢ĶF╦■ĪĘŻ¼┤╦ĢrSimiī”“░ŻĘŲĀ¢ĶF╦■”ū÷│÷Ēææ¬Ż®
S3Ż║ī”╔Žę╗▓ĮĘųį~Ą├ĄĮĄ─ĮY╣¹▀Mąą▒╚▌^Ż¼┼ąöÓ╩Ūʱ┤µį┌Ųń┴xŻ¼╚ń╣¹┤µį┌Ųń┴xŻ¼Š═▀Mąąę╗Č©Ą─Ųń┴xŽ¹ĮŌŻ╗
S4Ż║ųžÅ═S2ĪóS3Ż¼ų▒ĄĮ╠Ä└Ē═Ļ▓Į¾Eę╗ųąöÓŠõ╦∙ŪąĘų│÷Ą─╦∙ėąŠõūėå╬į¬ĪŻ
╦ŃĘ©┴„│╠╚ńłD╦∙╩ŠŻ║
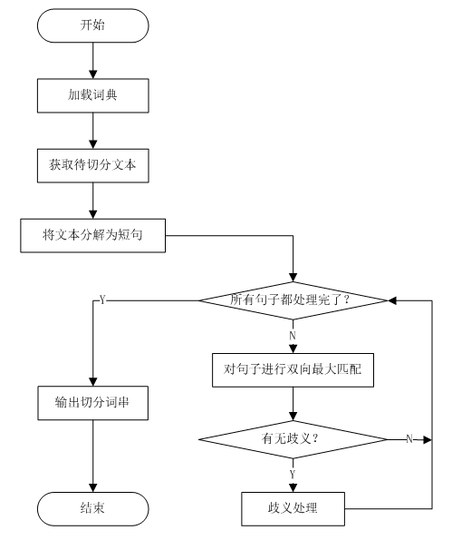
▀@└’Įo│÷┼cąĪ³Sļuī”įÆĄ─└²ūėŻ║╬ęå¢ąĪ³SļuŻ║“░ŻĘŲĀ¢ĶF╦■╔Ž45Č╚ĮŪč÷═¹ąŪ┐š”ĪŻ
S1Ż║ļpŽ“ūŅ┤¾Ųź┼õĘųį~Ż║š²Ž“Ę┤Ž“Š∙×ķĪČ░ŻĘŲĀ¢ĶF╦■╔ŽŻ¼45Č╚ĮŪŻ¼č÷═¹ąŪ┐šĪĘŻ¼ø]ėąŲń┴xĪŻķLį~ā׎╚Ż¼ŽĄĮy▀xō±┴╦“░ŻĘŲĀ¢ĶF╦■╔Ž”ū„×ķĻPµIį~Ż╗
S2Ż║ŽĄĮyį┌ų¬ūRÄņųąė├äé▓┼šfĄ─╣■ŽŻ║»öĄfŻ©░ŻĘŲĀ¢ĶF╦■╔ŽŻ®Ż¼šęĄĮ▒╚╚ń[░ŻŻ¼11Ż¼P] Ą─▒ĒĒŚŻ¼Ēśų°ųĖßśšęĄĮ6ūųį~Ą─╦„ę²Ż¼Ēśų°╦„ę²šęĄĮ6ūųį~▒ĒŻ¼▒ķÜvį~▒ĒŻ¼šęĄĮ<░ŻĘŲĀ¢ĶF╦■╔ŽŻ¼…>ĮYśŗ¾wŻ╗
S3Ż║ŽĄĮyļSÖC▀xō±įōĮYśŗ¾wAnsė“ųąĄ─ę╗éĆ╗ž┤Ż©ę▓ėą┐╔─▄╩ŪĖ∙ō■Ņl┬╩Ė▀Ą═üĒ▀xō±Ż®ĪŻ▒╚╚ń“ā╔─Ļų«║¾Ą╚ų°─Ń”ĪŻ
S4Ż║▌ö│÷╗ž┤Ż¼Ųź┼õĮY╩°ĪŻ
Part 3 ╚ń║╬ūįųŲąĪ³Sļu
Ė∙ō■Ą┌Č■▓┐Ęų╦∙ĮķĮBĄ─įŁ└ĒŻ¼éĆ╚╦Žļ꬚µš²═Ļ│╔š¹éĆąĪ³SļuĄ─ųŲū„╩ŪėąļyČ╚Ą─ĪŻ╚ń╣¹─▄ū÷│÷ę╗éĆųŪ─▄▌^Ė▀Ą─┴─╠ņÖCŲ„╚╦Ż¼─Ūų▒Įė┐╔ęį╚ź╔ĻšłīŻ└¹ķ_╣½╦Š┴╦~
╦∙ęįį┌▀@└’╬ęéāĮķĮBā╔ĘN▒╚▌^║åå╬ęūąąĄ─ĘĮĘ©Ż¼╠°▀^ī”ųŪ─▄╦ŃĘ©Ą─蹊┐Ż¼ų▒Įėš{ė├SimSimiĄ─ÄņĪŻ
3.1 ═©▀^½@╚ĪCookiesĘĮĘ©
╩ūŽ╚╬ęéāüĒ┐┤╚╦╚╦ŠWąĪ³Sļu╩Ūį§├┤ū÷Ą─ĪŻ
įŁū„š▀łFĻĀį┌github╔ŽĮo│÷┴╦į┤┤·┤aŻ¼ŠWųĘhttps://github.com/wong2/xiaohuangjiŻ¼╦¹éā╩╣ė├PythonšZčįŻ¼½@╚ĪCookiesŻ¼═©▀^╚╦╚╦ŠWĄ─Įė┐┌Ż¼īóSimiĄ─Äņ▀BĮėĄĮ╚╦╚╦╔ŽĪŻ
ę▓Š═╩ŪšfŻ¼╚╦╚╦ŠWąĪ³Sļu▓óø]ėąšµš²čąŠ┐Ą┌Č■▓┐ĘųųvĄĮĄ─ AI┴─╠ņÖCŲ„╚╦Ą─╦ŃĘ©Ż¼Č°╩Ū═©▀^š{ė├╚╦╝ęSimiĄ─ÄņŻĪ▀@Š═╩Ū╚╦╚╦ŠWąĪ³SļuĖ·SimiĄ─ĻPŽĄĪŻ
CookiesŻ║ųĖ─│ą®ŠWšŠ×ķ┴╦▒µäeė├æ¶╔ĒĘ▌Īó▀MąąsessionĖ·█ÖČ°ā”┤µį┌ė├æ¶▒ŠĄžĮKČ╦╔ŽĄ─öĄō■Ż©═©│ŻĮø▀^╝ė├▄Ż®ĪŻ└¹ė├ŠWĒō┤·┤aųąĄ─HTTPŅ^ą┼Žó▀Mąąé„▀fĪŻ
Ż©┼eéĆ└§ūėŻ¼╬ęéāĄ┌ę╗┤╬ĄŪõø▒Żčąšōē»Ģr▌ö╚ļė├æ¶├¹┼c├▄┤aŻ¼╚╗║¾▀xō±▒Ż┤µ├▄┤aŻ¼Š═ŽÓ«öė┌▒Ż┤µCookiesŻ¼Ž┬┤╬į┘┤“ķ_eebanŠ═▓╗ė├į┘ĄŪõø┴╦~
Cookiesū„×ķę╗éĆ┤¾ėąė├╠ÄĄ─┤µį┌Ż¼═¼Ģrę▓śO┤¾Ąž╬Ż║”ų°ŠWĮją┼Žó░▓╚½ĪŻę“×ķ╩Ū┐╔ęį═©▀^└²╚ńJS─_▒ŠĄ╚ĘĮĘ©Ė`╚ĪCookiesĄ─ĪŻŽļŽļ┐┤Ż¼äe╚╦½@╚Ī┴╦─ŃĄ─CookiesŻ¼Č╝▓╗ė├ų¬Ą└─ŃĄ─ė├æ¶├¹├▄┤aŠ═─▄ęį─ŃĄ─╔ĒĘ▌▓ķ┐┤Ó]╝■Ż¼×gė[ŠWĒōĄ╚Ą╚……«ö╚╗▀@╩ŪŅ}═ŌįÆŻ¼ėą┼d╚żĄ─╬ęéāęį║¾ėæšō~╦∙ęįŽŻ═¹┤¾╝ę─▄Įø│ŻŪÕ└Ēūį╝║Ą─CookiesŻ¼▓╗Įoē─╚╦┐╔│╦ų«ÖC~~Ż®
╗žĄĮ╬ęéāĄ─ąĪ³SļuŻ¼Ž┬łD╩Ū╚╦╚╦ŠWąĪ³Sļuį┤┤·┤aųąĻPė┌½@╚ĪCookiesĄ─ę╗Č╬Ż║
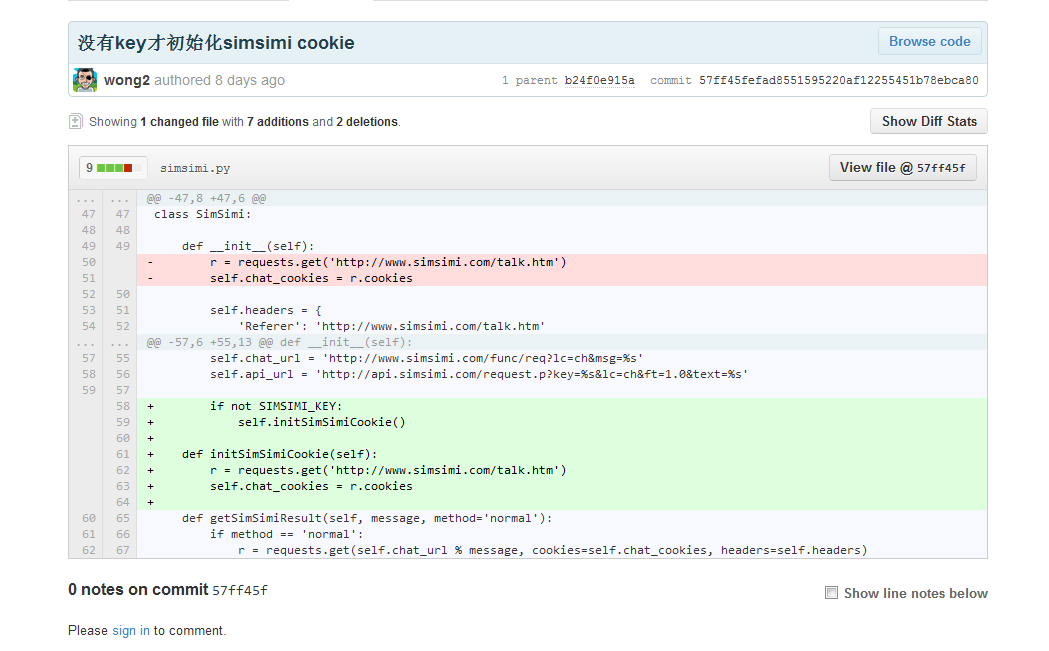
╬ęéāę¬ūįųŲ─žŻ¼Š═▓╗ė├╦¹éā─Ū├┤┬ķ¤®~į█éāų╗ę¬ÄūąąąĪ┤·┤aŠ═┐╔ęį┴╦~
║åå╬ĮķĮBę╗Ž┬║╦ą─╦ŃĘ©Ż║
S1Ż║└¹ė├sessionī”Ž¾½@╚Ī▒ŠÖCį┌http://www.simsimi.com/talk.htm ╔ŽĄ─Cookies
Ż©sessionŻ¼į┌ŠWĮjæ¬ė├ųą▒╗ĘQ×ķ“Ģ■įÆ”ĪŻ║åå╬ĄžšfŻ¼╦³Š═Ž±į┌ŠWšŠĒöīėĄ─ę╗éĆ║ąūėŻ¼¤ošōŠWĒōį§├┤╠°▐DŻ¼Č╝─▄ē“▒Ż┤µė├æ¶Ą─ą┼ŽóĪŻ▀@└’ūóęŌŻĪTalkĒō╩ŪSimi├Ō┘MĄ─┴─╠ņĒō├µŻ¼▀@ę╗³c║▄ųžę¬ŻĪŻ®
S2Ż║śŗįņŅ^ą┼ŽóŻ¼£╩éõīóCookies╠Ē╝ėį┌HTTPŅ^▓┐ą┼Žóųą
S3Ż║Å─SimSimi APIĮė┐┌ųą½@╚Ī▒ŠÖCĄ─Ēææ¬
Ż©äé▓┼šf▀^Ż¼Cookies└¹ė├HTTPŅ^ą┼Žó▀Mąąé„▀fŻ¼╦∙ęį╬ęéāīóäé▓┼talkĒō╔ŽĄ─Cookies╠Ē╝ėį┌ APIĒō╔ŽŻ¼ŽÓ«öė┌╩ŪtalkĒōį┌š{ė├APIŻĪŻĪŻĪ▀@ę╗³c║▄ųžę¬ĪŻ
┼eéĆ└§ūėŻ¼╬ęéā─├ų°ę╗░čµiŻ¼╚źšętalkĒōŻ¼talkĮo┴╦╬ęéāę╗░čĶĆ│ūŻ¼Ą½╩Ū╬ęéāķ_µi╩ųĘ©╬ęéā▓╗ų¬Ą└Ż¼ė┌╩Ū╬ęéāīóµi+ĶĆ│ūę╗Ų╦═ĮoAPIŻ¼╚╗║¾╦³Ä═╬ęéā┤“ķ_┴╦║ąūė~~~bling~~bling~~Ż®
üĒŻ¼╬ęéā┐┤┐┤įŁ└ĒłDŻ║
Ž┬├µ╩Ū╬ęė├▀@éĆĘĮĘ©ū÷Ą─ąĪ³Sļu1╠¢Ż║
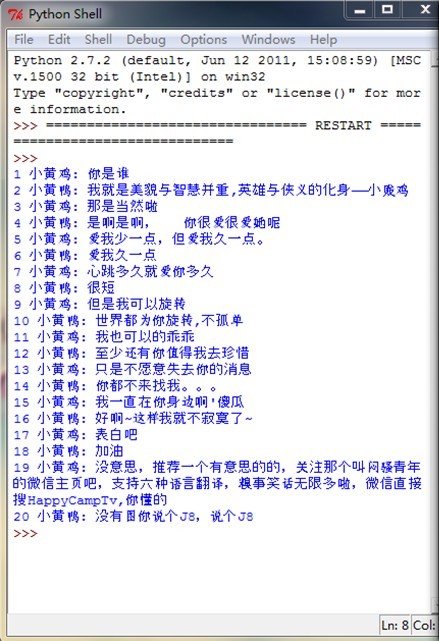
┤_ŪąĄ─šf╩Ū▀@╩Ūę╗ų╗ąĪ³Sļu┼cę╗ų╗ąĪ³S°åĄ─╗źŲ■ĪŻ╣■╣■ŻĪ
Žļę¬ū÷ąĪ³SļuŻ¼▀@╩Ūę╗éĆ╩ĪĢr╩Ī┴”Ą─ĘĮĘ©Ż¼Ą½╩ŪĪŻĪŻĪŻ▓╗Ą├▓╗šf▀@╩Ūį┌▒Iė├SimSimiĄ─ä┌äė│╔╣¹ĪŻĪŻĪŻ╚╦╝ęųĖ═¹╦³Ą─APIÄņ┘uÕXĄ──žĪŻĪŻĪŻĪŻŅ~Ņ~Ņ~
╦∙ęįĮėŽ┬üĒ╬ęéāüĒ┐┤š²░µĄ─ųŲū„ĘĮĘ©~~
3.2 ═©▀^keyš{ė├APIĮė┐┌
Ž┬├µ▀@éĆŠWųĘĮo│÷┴╦SimSimiĄ─╣┘ĘĮAPI╬─ÖnŻ║http://developer.simsimi.com/api
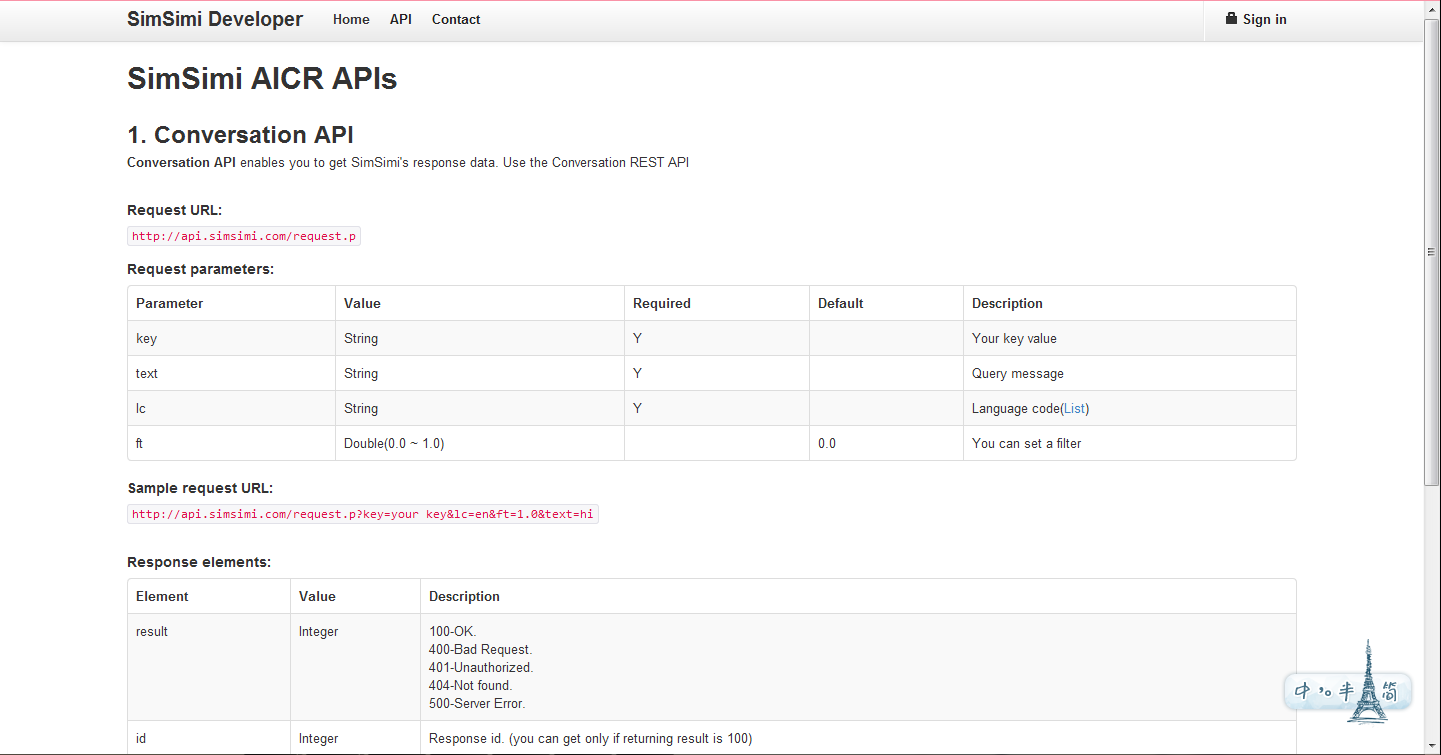
╬─ÖnęčĮøīæĄ├ĘŪ│ŻŪÕ╬·┴╦Ż¼http://api.simsimi.com/request.p?key=your key&lc=en&ft=1.0&text=hi▀@ę╗ąą┤·┤aŠ═╩Ūį┌š{ė├╣┘ĘĮAPIĮė┐┌ŻĪę▓Š═╩ŪšfŻ¼ų╗ę¬─Ń╔ĻšłĄĮ┴╦keyŻ¼Š═─▄š{ė├simiĄ─APIŻ¼╩Ū▓╗╩ŪŽļŽļŠ═║▄╦¼Ż┐~ūŅķ_╩╝╬ęĮo┤¾╝ęĄ─ąĪ³Sļu2╠¢Š═╩Ūš²░µļuėą─Šėą~¼Fį┌üĒųvĮŌę╗Ž┬į§├┤ū÷ĪŻ╬ę▀xō±J2EEŲĮ┼_Ż¼MVC─Ż╩ĮŻ¼JSP+JAVAšZčįĪŻ
ūŅ║╦ą─Ą─╦╝Žļ╩Ū▀@śėĄ─Ż║╬ęéāīóÅ─▒Ēå╬ųą½@╚ĪĄ─ūųĘ¹┤«Ż¼╦═╚źš{ė├╣┘ĘĮAPIĮė┐┌Ż¼ė├requestī”Ž¾ĘĄ╗žĮY╣¹Ż¼į┘┤“ĄĮŲ┴─╗╔Ž~~╩Ū▓╗╩Ū║▄║åå╬Ż┐
Ž┬├µĮķĮBįö╝Ü╦ŃĘ©┴„│╠Ż║
S1Ż║talk.jsp——ė├æ¶╠Ņīæ▒Ēå╬ā╚╚▌Ż¼īóģóöĄString texté„▀fĮochuil.jspŻ╗
S2Ż║chuli.jsp——requestī”Ž¾½@╚Īé„▀füĒĄ─ģóöĄŻ¼š{ė├APIŻ¼ė├ContentŅÉųąĄ─getContent(urls)ĘĮĘ©½@╚ĪŠWĒōĄ─ā╚╚▌Ż¼ĘĄ╗žĮY╣¹String ansŻ¼īóansé„▀fĮotalk.jspŻ╗
S3Ż║talk.jsp——requestī”Ž¾½@╚Īé„▀füĒĄ─ģóöĄansŻ¼īóans┤“ėĪĄĮŲ┴─╗╔ŽĪŻĮY╩°ĪŻ
*ŲõųąContentŅÉė├ė┌½@╚ĪŠWĒōā╚╚▌Ż¼ų▒Įė╔ŽŠWšęĄ─Ż¼Č╝▓╗ė├ūį╝║īæ~hiahia
▀@╩ŪąĪ³Sļu2╠¢Ą─ą¦╣¹łDŻ║
š²░µĄ─ĘĮĘ©Š═╩Ū║åå╬~Ą½╩Ūę“×ķ╩Ūš²░µĄ─Ż¼Š═Ą├ĖČ│÷┤·ārŻ¼key╩Ūę¬ÕXĄ─ĪŻ╬ę¼Fį┌ė├Ą─╩Ūįćė├░µŻ¼keyĄ─ėąą¦Ų┌Ž▐╩Ū90╠ņŻ¼▓óŪę├┐╠ņų╗ėą100┤╬Ēææ¬Ż¼ę▓Š═╩Ūšf─Ńę╗╠ņų╗─▄š{æ“╦³100┤╬ĪŻĪŻĪŻ╩Ū▓╗╩Ū║▄╔ŻĖąĪŻ
┐éĮY
Įø▀^▀@├┤ČÓĄ─ĮķĮBŻ¼┤¾╝ę╩Ū▓╗╩Ūī”ŅÉ╦ŲąĪ³SļuŻ©SimSimiŻ®Ą─╚╦╣żųŪ─▄┴─╠ņÖCŲ„╚╦ėą┴╦│§▓ĮĄ─šJūRĪŻŲõīŹ─Ń┐╔ęįū÷║▄ČÓų╗“ąĪ³Sļu”Ż¼Ą½╦³Ą─║╦ą─Č╝╩ŪSimsimiĄ─ÄņŻ¼╩Ū╚╦╝ęĄ─¢|╬„ĪŻ╦∙ęįšf┼╝éāą┬Ģr┤·Ą──Ļ▌p╚╦æ¬įōę¬ėąūį╝║äōą┬ęŌūR~ūī╬ęéāüĒķ_░lūį╝║Ą─ųŪ─▄╦ŃĘ©~ū÷ūį╝║Ą─ąĪ³SļuĪóąĪ³S°åĪóąĪ³S╣ĘĪóąĪ³S╣Ž░╔ŻĪ~~
å¢┤Łh╣Ø
ė¢ŠÜĄ─įÆ═µ╝ęš{æ“╦³Ą─öĄō■Ģ■▒╗õø╚ļū„×ķęį║¾╗ž┤äe╚╦Ą─ģó┐╝├┤Ż┐▀Ć╩ŪąĶꬎÓæ¬ÖÓŽ▐▓┼─▄┤µ╚ļÄņ└’Ż┐
▀@éĆŠ═╩ŪĮ╠īWĮń├µĪŻĢ■Ą─ĪŻ═µ╝ęĮ╠Įo╦³Ą─įÆŅ}Ż¼Ģ■į┌Ūąį~ų«║¾Ż¼┤“░³╦³Ą─╗ž┤Ż¼ę╗Ų┤µ╚ļį~ÄņĪŻäe╚╦ė|░lŽÓ╦ŲĄ─ĻPµIį~Ż¼ę▓ėą┐╔─▄╗ž┤äéäé─ŃĮ╠▀^Ą─┤░ĖĪŻ
─Ūę╗éĆå¢Ņ}ėą▓╗═¼┤░ĖŻ¼╚ń║╬▀xō±─žŻ┐
ę╗éĆĻPµIį~Ž┬µ£Įė┴╦║├ÄūĘN▓╗═¼Ą─╗ž┤Ż¼ŽĄĮyĢ■ļSÖC▀xō±ę╗éĆŻ¼▒╚╚ń▌ö╚ļ“╣■╣■”Ż¼╗ž┤ėą┐╔─▄╩Ū“║Ū║Ū”“ą”╩▓├┤ą””……
ęįŪ░Ą─▀@éĆį~▒Ē└’├µī”ė┌├┐éĆ┐╔─▄│÷¼FĄ─į~ęčĮøėą┴╦┤_Č©Ą─┤░ĖĄ─ęŌ╦╝å߯┐
ī”Ż¼śŗĮ©į~ÄņĄ─Ģr║“Ż¼▀Ćėąė¢ŠÜĄ─Ģr║“Č╝ęčĮøīæ▀M╚ź┴╦
Ą½╩Ūė¢ŠÜĄ─Ģr║“▓╗─▄ļS▒ŃĄ─░╔Ż┐╚fę╗Į╠╦¹Ą─╩ŪÕeš`Ą─ų¬ūR─žŻ┐
šlČ╝┐╔ęį~~Ą½╩Ūę╗░ŃĢ■ėą▀^×VŽĄĮyŻ¼ę¬īÅ║╦Ą─Ż¼Ž±simiŠ═ėąū÷╚╬äš▀@éĆ═µĘ©Ż¼╚╬䚊═╩ŪŻ¼Įo─Ńäe╚╦Ą─╗ž┤Ż¼ūī─Ń┼ąöÓ╩Ūʱ┐╔ęįĮo▓╗ØM16ÜqĄ─║óūė┐┤Ż¼ę▓ėą┤µ▀M╚źĄ─Ģr║“įOų├├¶Ėąį~╩▓├┤Ą─ĪŻ