
Instagram╩Ūę╗╝ę╗∙ė┌iOS║═AndroidĄ─╔ńĮ╗łDŲ¼ššŲ¼ĘųŽĒæ¬ė├ķ_░l╔╠ĪŻæ{ĮĶų°¬Ü╠žĄ─▀\ĀI└Ē─ŅŻ¼ūį2010─Ļ3į┬│╔┴óęįüĒŻ¼Č╠Č╠ę╗─ĻĄ─ĢrķgŠ═╬³ę²┴╦1400╚fė├æ¶ĪŻČ°║¾ļSų°╩ųÖCŽÓÖCĖ─äėĪółDŽ±╠Ä└Ē╔²╝ēĪó┼cFacebookĄ╚╔ńĮ╗ņ`╗ŅĮ╗╗źĪóų¦│ųAndroidĄ╚Ę■äš▓╗öÓ╔²╝ēŻ¼ė├æ¶┴┐čĖ╦┘ø_ō¶3000╚fŻ¼ė┌2012─Ļ9į┬▒╗Facebookęį7.15ā|├└į¬╩š┘ÅĪŻČ°Įžų╣ĄĮĮ±─Ļ2į┬ĄūŻ¼Ųõ╗Ņ▄Sė├æ¶│╔╣”═╗ŲŲ1ā|ĪŻ

Instagramā╔╬╗äō╩╝╚╦
┼cĖ▀╦┘į÷ķLŽÓ▒│ļxĄ─╩ŪŻ¼Å─│╔┴óų«│§āHėąäP╬─·ŽŻ╦╣╠ž┴_─Ę(Kevin Systrom)║═▀~┐╦·┐╦└’Ė±(Mike Krieger)ā╔╬╗äō╩╝╚╦Ż¼ĄĮ2011─Ļ½@Ą├A▌å’L═Č700╚f├└į¬Ą─4╬╗åT╣żŻ¼į┘ĄĮ▒╗╩š┘ÅĢrĄ─13╚╦łFĻĀŻ¼Instagram╚╦åTĮM┐Śę╗ų▒śO×ķŠ½║åĪŻ
╚ń┤╦ąĪęÄ─ŻĄ─łFĻĀŠė╚╗┐╔ęį╚ń┤╦ūį╚ńĄžæ¬ī”’w╦┘į÷ķLĄ─ė├æ¶öĄ▓ó╠ß╣®äōą┬Ę■䚯¼▀@▓╗─▄▓╗šf╩Ū╣Ķ╣╚Ą─ėųę╗éĆžöĖ╗é„ŲµĪŻęįų┴ė┌Instagram╝╝ągłFĻĀū½īæĄ─ĪČInstagramŻ║öĄ░┘Ą─īŹ└² ┤¾┴┐Ą─╝╝ągĪĘę╗Įø░l▓╝Ż¼Š═½@Ą├┴╦äōśIŲ¾śICTOéāĄ─¤ß┴ę╗žæ¬ĪŻ▒╦ĢrŻ¼InstagramĄ─łFĻĀ▀Ćį┌īżšęę╗éĆ“┐╔ęį±ZĘ■EC2 īŹ└²╚║Ą─DevOps”ĪŻ
ø]ėąŽļĄĮŻ¼╩š┘Å╚ń┤╦üĒä▌ø░ø░ĪŻ2012─Ļ4į┬10╚šŻ¼Facebooką¹▓╝╩š┘ÅInstagramĪŻā╔╠ņų«║¾Ż¼InstagramĄ─┬ō║Žäō╩╝╚╦Mike Krieger╣½ķ_░l▒ĒĪČ╚ń║╬│╔×ķ╩«ā|├└į¬╣½╦ŠĪĘč▌ųvŻ¼Ą┌ę╗┤╬Ž“═ŌĮń╚½├µĄžš╣¼F┴╦InstagramäōśIÜv│╠ęį╝░Ųõųą▓╗Ą├▓╗šfĄ─╝╝ąg“├ž├▄.”ĪŻ▒Š╬─×ķč▌ųvPPT╚½╬─ĘŁūgŻ¼ėąų·ė┌äōą┬╝╝ągłFĻĀĖ³║├šJūR║═┴╦ĮŌInstagram13╚╦łFĻĀäōįņŲµ█E╦∙ę└┘ćĄ─╝╝ągŻ║
Instagram╝╝ągłFĻĀŻ║
- 2010─ĻŻ║ 2╬╗╣ż│╠Ĥ
- 2011─ĻŻ║ 3╬╗╣ż│╠Ĥ
- 2012─ĻŻ║ 5╬╗╣ż│╠Ĥ
Instagram║╦ą─įŁätŻ║
- 1 simplicity(║åØŹų„┴x)
- 2 optimize for minimal operational burden(×ķ▒M┴┐£p╔┘▀\ŠSžōō·Č°ā×╗»)
- 3 instrument everything(▒O┐žę╗Ūą)
ę╗Īó│§äōļAČ╬Ż║
ā╔├¹ø]ėą╚╬║╬║¾Č╦Ą─īŹæĮø“ץ─äō╩╝╚╦Ż╗
═©▀^═ą╣▄į┌┬Õ╔╝┤ē─│╠ÄĄ─ę╗┼_ÖCŲ„Ż©╔§ų┴ąį─▄Č╝ø]ėąMacBook ProÅŖŻ®Ż╗
┤µā”▓╔ė├CouchDBŻ©Apache CouchDB ╩Ūę╗éĆ├µŽ“╬─ÖnĄ─öĄō■Äņ╣▄└ĒŽĄĮyŻ®Ż╗
«aŲĘ╔ŽŠĆĄ┌ę╗╠ņėą25000ūóāįė├æ¶ĪŻ
Č■Īó╔ŽŠĆļAČ╬Ż║
ę“×ķ═³ėøfavicon.icołDś╦╬─╝■Ż¼į┌Django╔Žę²Ų┤¾┴┐404Õeš`ĪŻ
▀@╩ŪĄ┌ę╗éĆĮø“×Į╠ė¢ĪŻ║¾├µ▀ĆėąŻ║
ulimit -n Ż¼įOų├Linuxā╚║╦┐╔ęį═¼Ģr┤“ķ_Ą─╬─╝■├Ķ╩÷Ę¹Ą─ūŅ┤¾ųĄŻ¼└²╚ńsize×ķ4092ĪŻ
memcached -t 4Ż¼įOų├ė├ė┌╠Ä└ĒšłŪ¾Ą─ŠĆ│╠öĄĪŻ
prefork/postfork ŠĆ│╠Ą─ŅA╝ė▌d▀Ć╩Ū║¾╝ė▌dĪŻ
’@╚╗Ż¼Į^┤¾ČÓöĄŽĄĮyöUš╣å¢Ņ}Ę▒¼ŹČ°└¦ļyĪŻČ°į┌▓╗öÓ│÷¼Få¢Ņ}▓óĮŌøQå¢Ņ}Ą─▀^│╠ųąŻ¼InstagramøQČ©▀w═∙AWSĄ─EC2ĪŻ
╚²Īó▀węŲļAČ╬Ż║
“let’s move to EC2”Š═Ž±╩Ū“ī”100┤a╦┘Č╚ąą±éĄ─Ų¹▄ćĖ³ōQ╦∙ėą▓┐╝■”ĪŻ

Š▀¾wĘų╬÷Ż║
1. öĄō■ÄņöUš╣
įńŲ┌Ż║django ORM+postgresqlŻ©PostGISŻ®
ę“×ķPostGISČ°▀xō±┴╦postgresqlŻ¼PostGISį┌ī”Ž¾ĻPŽĄą═öĄō■ÄņPostgreSQL╔Žį÷╝ė┴╦┤µā”╣▄└Ē┐šķgöĄō■Ą──▄┴”Ż¼ŽÓ«öė┌OracleĄ─spatial▓┐ĘųŻ¼öĄō■Äņ┐╔▓┐╩į┌¬Ü┴óĘ■äšŲ„╔ŽĪŻ
ļSų°ššŲ¼öĄ┴┐Ą─▒¼░l╩Įį÷ķLŻ¼ūŅ┤¾ā╚┤µ×ķ68GĄ─EC2’@╚╗¤oĘ©ų¦│ųĪŻ
Ė─ūāŻ║▀Mąąvertical partitioningŻ©┤╣ų▒Ęųģ^Ż®Ż¼▓ó═©▀^django db routers╩╣┤╣ų▒Ęųģ^Ė³╝ė╚▌ęūĪŻ
╚ńŻ║ššŲ¼ätė│╔õĄĮphotodb
def db_for_read(self, model):<br> if app_label == 'photos':<br> return 'photodb'
ÄūéĆį┬ęį║¾Ż¼photodb>60GĄ─Ģr║“Ż¼▓╔ė├horizontal partitioningŻ©╦«ŲĮĘųģ^Ż¼ė├“ĘųŲ¼”shardingīŹ¼F)
Ą½shardingę▓ĦüĒųTČÓå¢Ņ}Ż║
1Ż®. öĄō■Öz╦„Ż©ČÓöĄŪķørŽ┬Ż¼║▄ļyų¬Ą└ė├æ¶Ą─ų„įLå¢─Ż╩ĮŻ®
2Ż®. «öėąĘųŲ¼ūāĄ├╠½┤¾Ą─Ģr║“į§├┤▐kŻ┐
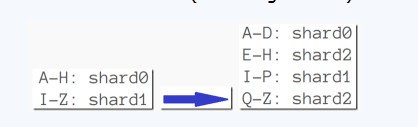
┐╔ęį▓╔ė├Ż¼╗∙ė┌ĘČć·Ą─ĘųŲ¼▓▀┬į(╚ńMongoDBę╗śė)

3Ż®. ąį─▄Ž┬ĮĄŻ¼╠žäe╩Ūė╔EC2īŹ└²┤┼▒PIOī¦ų┬Ż¼ĮŌøQĘĮĘ©╩ŪŻ║ŅAŽ╚ŪąĘų(pre-split)Ż¼╝┤ŅAŽ╚ŪąĘų╔ŽŪ¦éĆ▀ē▌ŗŪąŲ¼Ż¼īó╦³éāė│╔õĄĮ▌^╔┘Ą─╬’└ĒĘųģ^╣سcųą╚źĪŻ


2. ▀xō±║Ž▀m╣żŠ▀
▀MąąŠÅ┤µ/Ę┤ęÄĘČ╗»öĄō■įOėŗ
ė├æ¶╔Žé„łDŲ¼ĢrŻ║
1). ė├æ¶╔Žé„Ħėąś╦Ņ}ą┼Žó║═Ąž└Ē╬╗ų├ą┼Žó(┐╔▀x)Ą─ššŲ¼Ż╗
2). ═¼▓ĮīæĄĮ▀@éĆė├æ¶ī”æ¬Ą─öĄō■Äņ(ĘųŲ¼)ųąŻ╗
3). ▀MąąĻĀ┴ą╗»╠Ä└Ē
a ╚ń╣¹Ä¦ėąĄž└Ē╬╗ų├ą┼ŽóŻ¼═©▀^«É▓ĮĄ─POSTšłŪ¾Ż¼īó▀@éĆłDŲ¼Ą─ą┼Žó╦═ĄĮSolr(Instagram ė├ė┌geo-search APIĄ─╚½╬─Öz╦„Ę■äšŲ„)ĪŻ
b Ė·ļSš▀Ą─ą┼ŽóĘų░l(follower delivery)Ż¼╝┤ĖµįV╬ęĄ─follower Ż¼╬ę░l▓╝┴╦ą┬Ą─ššŲ¼ĪŻ╚ń║╬üĒīŹ¼FĄ──žŻ┐├┐éĆė├æ¶Č╝ėąę╗éĆfollower ┴ą▒ĒŻ¼ą┬ššŲ¼╔Žé„ĢrĢ■░čššŲ¼ID░l╦═Įo┴ą▒ĒųąĄ─├┐ę╗éĆė├æ¶Ż¼ė├Redis üĒ╠Ä└Ē▀@ę╗śIäš║åų▒╠½░¶┴╦Ż¼┐ņ╦┘▓Õ╚ļŻ¼┐ņ╦┘ūė╝»╗»ĪŻ
c «öąĶę¬╔·│╔feedĄ─Ģr║“Ż¼╬ęéā═©▀^ID+#Ą─Ė±╩ĮŻ¼ų▒Įėį┌memcachedųą▓ķšęą┼Žó
Redis▀m║Ž╩▓├┤śėĄ─ł÷Š░Ż┐
1).öĄō■ĮYśŗŽÓī”ėąŽ▐Ż╗
2).ī”ŅlĘ▒GETĄ─ĄžĘĮŻ¼ī”Å═ļsī”Ž¾▀MąąŠÅ┤µŻ╗
▓╗ę¬īóūį╝║ĮēČ©į┌ĘŪĄ├ęįā╚┤µöĄō■Äņ×ķų„ę¬┤µā”▓▀┬įĄ─ĘĮ░Ė╔ŽĪŻ
ĻPė┌FollowłDūV
Ą┌ę╗░µŻ║║åå╬Ą─öĄō■Äņ▒ĒĖ±Ż©source_ id, target_id, status)
ąĶę¬üĒ╗ž┤╚ńŽ┬▓ķįāŻ║╬ęĻPūóšlŻ┐šlĻPūó╬ęŻ┐╬ę╩ŪʱĻPūó─│╚╦Ż┐─│╚╦╩ŪʱĻPūó╬ęŻ┐
«ööĄō■ÄņĄ─ē║┴”ūā┤¾ĢrŻ¼Instagramķ_╩╝į┌Redisųą▓ó░l┤µā”ĻPūółDūVŻ¼Ą½▀@ę▓ĦüĒ┴╦ā╚╚▌ę╗ų┬ąįŻ©consistencyŻ®Ą─å¢Ņ}ĪŻČ°▓╗ę╗ų┬ąįę╗Č╚Ģ■ĦüĒŠÅ┤µ╩¦ą¦å¢Ņ}ĪŻ
PostGISĮY║Ž▌p┴┐Ą─memcachedŠÅ┤µŻ¼┐╔ęįų¦ō╬╔Ž╚fĄ─šłŪ¾┴┐ĪŻ
ąĶę¬ūóęŌ³cŻ║
1). ║╦ą─öĄō■┤µā”▓┐Ęųėąę╗éĆ╚f─▄Ą─ĮM╝■ų¦ō╬Ż¼Š═Ž±Ż║RedisŻ╗
2).Ū¦╚f▓╗ę¬įćŽļė├ā╔ĘN╣żŠ▀╚źū÷═¼ę╗éĆ╣żū„Ż╗
3. ▒Ż│ų├¶Į▌
1). ÅVĘ║Ą─å╬į¬£yįć║═╣”─▄£yįć
2). łį│ųDRYŻ©Don’t Repeat YourselfŻ®įŁät
3). ╩╣ė├═©ų¬/ą┼╠¢ÖCųŲīŹ¼FĮŌ±Ņ
4). ╬ęéā┤¾▓┐Ęų╣żū„╩╣ė├PythonüĒ═Ļ│╔Ż¼ų╗ėą▒Ų▓╗Ą├ęčĄ─Ģr║“Ż¼▓┼Ģ■ė├C
5). ŅlĘ▒Ą─┤·┤aÅ═▓ķŻ¼▒M┴┐▒Ż│ų“ųŪ╗█╣▓ŽĒ”ĪŻ
6). ÅVĘ║Ą─ŽĄĮy▒O┐ž
4. ═∙AndroidŲĮ┼_öUš╣
12ąĪĢrį÷╝ė100╚fą┬ė├æ¶Ą─ĻPµIŻ║
1). éź┤¾Ą─╣żŠ▀┐╔ęį╩╣ūx╚ĪĖ³Š▀öUš╣ąįŻ¼└²╚ńŻ║redis: slaveof <host> <port>Ż©SLAVEOF ├³┴Ņė├ė┌į┌ Redis ▀\ąąĢräėæBĄžą▐Ė─Å═ųŲ(replication)╣”─▄Ą─ąą×ķŻ®Ż╗
2). Ė³Č╠Ą─Ą³┤·ų▄Ų┌Ż╗
3). ▓╗ę¬ųžÅ═░l├„▌åūėŻ¼└²╚ńŽļķ_░lę╗éĆŽĄĮy▒O┐žĄ─╩žūo▀M│╠Ż¼═Ļ╚½ø]ėą▒žę¬Ż¼HAProxy═Ļ╚½─▄ä┘╚╬▀@ę╗╣żū„Ż╗
4). šęÅŖ┤¾Ą─╝╝ągŅÖå¢Ż╗
5). ╝╝ągłFĻĀ▒Ż│ųķ_Ę┼Ą─Ęšć·▓óĘeśO╗žüķ_į┤╩└ĮńŻ╗
6). ĻPūóā×╗»Ż¼Žļ▐kĘ©ūīŽĄĮy╦┘Č╚┐ņ╔Žę╗▒ČĪŻ
7). ▒Ż│ų├¶Į▌Ż╗
8).╩╣ė├ūŅ╔┘▓┐╝■Ż¼ūŅĖ╔ā¶Ą─ĮŌøQĘĮ░ĖŻ╗
9). ▓╗ę¬▀^Č╚Ą─ā×╗»Ż¼│²ĘŪ─Ń╠ßŪ░ų¬Ą└ūį╝║Ą─ŽĄĮyīó╚ń║╬öUš╣
PPT║▄║├Ą─▒Ż│ų┴╦Instagram“simplicity”Ą─š▄īWŻ¼╝┤╩╣╠ߥĮ╝╝ągŻ¼ę▓Š½║åĄĮ┴╦śOų┬ĪŻ×ķ┴╦ūīĖ³ČÓ┼¾ėč├„┴╦Ż¼╠žäeÅ─Ųõ╣ż│╠Ĥ▓®┐═╔Ž▀xō±Ė³ČÓ╝Ü╣ØüĒčaūŃŻ¼Č°▀@└’Ż¼╩Ū▀@5╬╗╣ż│╠ĤīŹ█`Įø“ץ─┐éĮYŻ¼Ųõųą▓╗Ę”─Ūą®śO×ķīŹė├Ą─ķ_į┤╣żŠ▀ĪŻ
╦─ĪóŲõ╦¹╝Ü╣Ø╝╝ąg
1. ▓┘ū„ŽĄĮy/ų„ÖC
į┌Amazon EC2╔Ž┼▄Ubuntu Linux 11.04 (“Natty Narwhal”)Ż¼▀@éĆ░µ▒ŠĮø▀^“×ūCį┌ EC2 ╔Žē“ĘĆČ©ĪŻĄ½ų«Ū░Ą─░µ▒Šį┌EC2╔ŽĖ▀┴„┴┐Ą─Ģr║“Č╝Ģ■│÷¼FĖ„ĘN▓╗┐╔ŅA£yĄ─å¢Ņ}ĪŻ
2. žō▌dŠ∙║Ō
├┐ę╗éĆī”Instagram Ę■äšŲ„Ą─įLå¢Č╝Ģ■═©▀^žō▌dŠ∙║ŌĘ■äšŲ„Ż╗╬ęéā╩╣ė├2┼_NginxÖCŲ„ū÷DNS▌åįāĪŻ▀@ĘNĘĮ░ĖĄ─╚▒³c╩Ū«öŲõųąę╗┼_═╦ę█ĢrŻ¼ąĶę¬╗©ĢrķgĖ³ą┬DNSĪŻūŅĮ³Ż¼▐DČ°╩╣ė├AmazonĄ─ELB(Elastic Load Balancer)žō▌dŠ∙║ŌŲ„Ż¼╩╣ė├3éĆNginx īŹ└²┐╔ęįīŹ¼Fš{╚ļš{│÷(Č°«ö─│éĆNginxīŹ└²═©▓╗▀^╣╩šŽÖz£yŻ¼ŽĄĮyĢ■ūįäėīóŲõÅ─裣hųą│ķļx)Ż╗═¼Ģrį┌ ELB īė═ŻĄ¶┴╦ SSL , ęįŠÅĮŌnginxĄ─ CPU ē║┴”ĪŻ╩╣ė├AmazonĄ─Route53Ę■äšū„×ķDNSĘ■䚯¼▀@╩ŪAWS┐žųŲ┼_╔Žį÷╝ėĄ─ę╗╠ū║▄║├Ą─GUI╣żŠ▀ĪŻ
3. æ¬ė├Ę■äšŲ„
į┌AmazonĄ─High-CPU Extra-LargeÖCŲ„╔Ž▀\ąą┴╦Django Ż¼ļSų°ė├æ¶Ą─į÷ķLŻ¼ęčĮøį┌╔Ž├µ┼▄┴╦25éĆDjangoīŹ└²┴╦(ąę▀\ĄžŻ¼ę“×ķ╩Ū¤oĀŅæBĄ─Ż¼╦∙ęįĘŪ│Ż▒Ńė┌ÖMŽ“öUš╣)ĪŻĄ½░l¼FéĆäe╣żū„žō▌d╩Ūī┘ė┌ėŗ╦Ń├▄╝»ą═Č°ĘŪIO├▄╝»ą═Ż¼ę“┤╦High-CPU Extra-LargeŅÉą═Ą─īŹ└²äé║├╠ß╣®┴╦║Ž▀mĄ─▒╚ųž(CPU║═ā╚┤µ)ĪŻ
×ķ┤╦Ż¼╩╣ė├ Gunicorn ū„×ķ WSGI Ę■äšŲ„ĪŻ▀^╚źį°ė├▀^ Apache Ž┬Ą─ mod_wsgi ─ŻēKŻ¼▓╗▀^░l¼F Gunicorn Ė³╚▌ęū┼õų├▓óŪę╣Ø╩Ī CPU ┘Yį┤ĪŻ╩╣ė├ Fabric ╝ė╦┘▓┐╩ĪŻFabricūŅĮ³į÷╝ė┴╦▓óąą─Ż╩ĮŻ¼ę“┤╦▓┐╩ų╗ąĶę¬╗©┘MÄū├ļńŖĪŻ
4. öĄō■┤µā”
┤¾▓┐ĘųöĄō■(ė├æ¶ą┼ŽóŻ¼ššŲ¼Ą─į¬öĄō■Īóś╦║ץ╚)┤µā”į┌PostgreSQLųąŻ╗▓ó╗∙ė┌▓╗═¼Ą─Postgres īŹ└²▀MąąŪąĘųĄ─ĪŻų„ę¬ĘųŲ¼╝»╚║░³║¼12éĆ╦─▒Č│¼┤¾ā╚┤µįŲų„ÖC(Ūę12éĆĖ▒▒Šį┌▓╗═¼Ą─ģ^ė“)Ż╗
Č°üå±R▀dĄ─ŠWĮj┤┼▒PŽĄĮy(EBS)├┐├ļĄ─īżĄ└─▄┴”▓╗ē“Ż¼ę“┤╦Ż¼īó╦∙ėą╣żū„Ę┼ĄĮā╚┤µųąŠ═ūāĄ├ė╚×ķųžę¬ĪŻ×ķ┴╦½@Ą├║Ž└ĒĄ─ąį─▄Ż¼äōĮ©┴╦▄ø RAID ęį╠ß╔² IO ─▄┴”Ż¼╩╣ė├Ą─ Mdadm ╣żŠ▀▀Mąą RAID ╣▄└ĒŻ╗
▀@└’Ż¼vmtouchė├üĒ╣▄└Ēā╚┤µöĄō■╩ŪéĆśO║├Ą─╣żŠ▀Ż¼ė╚Ųõ╩Ūį┌╣╩šŽ▐DęŲĢrŻ¼Å─ę╗┼_ÖCŲ„ĄĮ┴Ēę╗┼_ÖCŲ„Ż¼╔§ų┴ø]ėą╗ŅäėĄ─ā╚┤µĖ┼ę¬╬─╝■Ą─ŪķørĪŻ▀@└’╩Ū─_▒ŠŻ¼ė├üĒĮŌ╬÷▀\ąąė┌ę╗┼_ÖCŲ„╔ŽĄ─vmtouch ▌ö│÷▓ó┤“ėĪ│÷ŽÓæ¬vmtouch├³┴ŅŻ¼į┌┴Ēę╗┼_ÖCŲ„╔Žł╠ąąŻ¼ė├ė┌Ųź┼õ╦¹«öŪ░Ą─ā╚┤µĀŅæBŻ╗
╦∙ėąĄ─PostgreSQLīŹ└²Č╝╩Ū▀\ąąė┌ų„-éõ─Ż╩Į(Master-Replica)Ż¼╗∙ė┌┴„Å═ųŲŻ¼▓óŪę╩╣ė├EBS┐ņššĮø│ŻéõĘ▌╬ęéāĄ─ŽĄĮyĪŻ×ķ┴╦▒ŻūC┐ņššĄ─ę╗ų┬ąį(įŁ╩╝ņ`ĖąüĒį┤ė┌ec2-consistent-snapshot)╩╣ė├XFSū„×ķ╬ęéāĄ─╬─╝■ŽĄĮyŻ¼═©▀^XFSŻ¼«ö▀Mąą┐ņššĢrŻ¼┐╔ęįā÷ĮY&ĮŌā÷RAIDĻć┴ąĪŻ×ķ┴╦▀Mąą┴„Å═ųŲŻ¼╬ęéāūŅÉ█Ą─╣żŠ▀╩Ūrepmgr ĪŻ
ī”ė┌Å─æ¬ė├Ę■äšŲ„▀BĮėĄĮöĄō■Ż¼╬ęéā║▄įńŠ═╩╣ė├┴╦Pgbouncerū÷▀BĮė│žŻ¼┤╦┼eī”ąį─▄ėąŠ▐┤¾Ą─ė░ĒæĪŻ╬ęéā░l¼FChristophe PettusĄ─▓®┐═ ėą┤¾┴┐Ą─ĻPė┌DjangoĪóPostgreSQL ║═Pgbouncer ├žįEĄ─┘Yį┤ĪŻ
ššŲ¼ų▒Įė┤µā”į┌üå±R▀dĄ─S3Ż¼«öŪ░ęčĮø┤µā”┴╦ÄūTĄ─ššŲ¼öĄō■ĪŻ╩╣ė├üå±R▀dĄ─CloudFrontū„×ķ╬ęéāĄ─CDNŻ¼▀@╝ė┐ņ┴╦╚½╩└Įńė├æ¶Ą─ššŲ¼╝ė▌dĢrķgĪŻ
×ķ┴╦geo-search APIŻ¼╬ęéāę╗ų▒╩╣ė├PostgreSQL┴╦║▄ČÓéĆį┬Ż¼▓╗▀^║¾üĒ▀węŲĄĮ┴╦Apache Solr.╦¹ėąę╗╠ū║åå╬Ą─JSONĮė┐┌Ż¼▀@śė╬ęéāĄ─æ¬ė├│╠ą“ŽÓĻPĄ─Ż¼ų╗╩Ū┴Ēę╗╠ūAPIČ°ęčĪŻ
ūŅ║¾Ż¼║═╚╬║╬¼F┤·WebĘ■äšę╗śėŻ¼╩╣ė├┴╦Memcached ū÷ŠÅ┤µŻ¼▓óŪę«öŪ░ęčĮø╩╣ė├┴╦6éĆMemcached īŹ└²Ż¼╬ęéā╩╣ė├pylibmc & libmemcached▀Mąą▀BĮėĪŻAmzonūŅĮ³åóė├┴╦ę╗éĆņ`╗ŅĄ─ŠÅ┤µĘ■äš(Elastic Cache service)Ż¼Ą½╩Ū╦³▓ó▓╗▒╚▀\ąą╬ęéāūį╝║Ą─īŹ└²▒Ńę╦Ż¼ę“┤╦╬ęéā▓óø]ėąŪąōQ╔Ž╚źŻ╗
5. ╚╬äšĻĀ┴ą&═Ų╦══©ų¬
«öę╗éĆė├æ¶øQČ©ĘųŽĒę╗ÅłInstagram Ą─ššŲ¼ĄĮTwitter ╗“FacebookŻ¼╗“š▀╩Ū«ö╬ęéāąĶę¬═©ų¬ę╗éĆ īŹĢrėåķåš▀ėąę╗Åłą┬Ą─ššŲ¼┘N│÷Ż¼╬ęéāīó▀@éĆ╚╬äš═ŲĄĮ GearmanŻ¼ę╗éĆ╚╬äšĻĀ┴ąŽĄĮy─▄ē“īæė┌DangaĪŻ▀@śėū÷Ą─╚╬äšĻĀ┴ą«É▓Į═©▀^ęŌ╬Čų°├Į¾w╔Žé„┐╔ęį▒M┐ņ═Ļ│╔,Č°“ųžō·”┐╔ęįį┌║¾┼_▀\ąąĪŻ╬ęéā┤¾Ė┼ėą200éĆ╣żū„īŹ└²(Č╝ė├PythonīæĄ─)į┌ĮoČ©Ą─Ģrķgā╚ī”ĻĀ┴ąųąĄ─╚╬äš▀MąąŽ¹┘MŻ¼▓óĘų░lĮo▓╗═¼Ą─Ę■äšĪŻ╬ęéāĄ─feed feed fan-outę▓╩╣ė├┴╦GearmanŻ¼▀@śėpostingŠ═Ģ■Ēææ¬ą┬ė├æ¶Ż¼ę“×ķ╦¹ėą║▄ČÓfollowersĪŻ
ī”ė┌Ž¹Žó═Ų╦═Ż¼šęĄĮĄ─ūŅäØ╦ŃĄ─ĘĮ░Ė╩ŪŻ¼ę╗éĆķ_į┤Ą─Twisted Ę■䚯¼ęčĮø×ķ╬ęéā╠Ä└Ē┴╦│¼▀^10ā|Śl═©ų¬Ż¼▓óŪęĮ^ī”┐╔┐┐ĪŻ
6. ▒O┐ž
╗∙ė┌ Python-Munin,īæ┴╦║▄ČÓMunin ▓Õ╝■Ż¼╩╣ė├Munin▀MąąłDą╬╗»Č╚┴┐ĪŻė├ė┌łDą╬╗»Č╚┴┐ĘŪŽĄĮy╝ēĄ─¢|╬„(└²╚ńŻ¼├┐├ļĄ─║×╚ļ╚╦öĄŻ¼├┐ŚlššŲ¼░l▓╝öĄĄ╚)Ż¼╩╣ė├Pingdomū„×ķ═Ō▓┐▒O┐žĘ■䚯¼PagerDuty ė├ė┌╩┬╝■═©ų¬ĪŻ
PythonÕeš`ł¾ĖµŻ¼╩Ū╩╣ė├Ą─SentryŻ¼ę╗éĆDisqusĄ─╣ż│╠ĤīæĄ─┴Ņ╚╦Š┤╬ĘĄ─ķ_į┤Ą─Django appĪŻį┌╚╬║╬ĢrķgŻ¼Č╝┐╔ęįīŹĢrĄ─▓ķ┐┤ŽĄĮy░l╔·┴╦╩▓├┤Õeš`ĪŻ
╬─š┬ĄĮ▀@└’Ż¼▓óø]ėąĮY╩°ĪŻī”Į±╠ņęčĮø┐ńįĮ“ā|”ŠĆĄ─InstagramČ°čįŻ¼“×ķ┴╦ūŅąĪĄ─▀\ĀIžōō·Č°ā×╗»│╠ą“Ż¼└¹ė├ę╗Ūą─▄ė├ĄĮĄ─Ż©ķ_į┤Ż®╣żŠ▀┼cįŲŲĮ┼_Ż¼śO║åĄ─╝╝ągų„Åł”╬┤ūāŻ¼▓╗ą┼Ż¼┐┤┐┤ūŅĮ³Ą─ą┬┬äŻ¼ĪČInstagramĄ─žō▌dŠ∙║Ō╬õŲ„Ż║Eureka╠Ņča┴╦Amazon Web ServicesĄ─┤¾╚▒┐┌ĪĘ▀Ćį┌└mīæī┘ė┌╦¹ūį╝║Ą─╝╝ągé„ŲµĪŻŻ©@╝tą─└ŅĄ─Ęų╬÷ī”▒Š╬─ę▓ėąžĢ½IŻ¼īÅąŻ/ų┘║ŲŻ®
µ£ĮėŻ║Mike KriegerĪČ╚ń║╬│╔×ķ╩«ā|├└į¬╣½╦ŠĪĘč▌ųvPPT